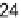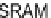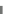Graphics Reference
In-Depth Information
a
b
W
W
Fig. 10.7
Eliminate read/write with registers for an SRAM-based transpose memory. (
a
) Pipeline
stall due to transpose SRAM delay for 32
32 TU. (
b
) Row caching to avoid stall
processed, the transform module must wait for it to be written to the SRAM before
it can begin processing the row. This results in a delay of nine cycles for 32
32
TU. In general, for an N
N TU, this delay is equal to N/4
C
1 cycles. This results
in a pipeline stall of 1.75-25 % cycles depending on the TU size. This stall can be
avoided through the use of a row cache that stores the first N
C
4 pixels in registers.
As shown in Fig.
10.7
b, the row cache is read for the first nine cycles of the row
transforms while the last column is being stored in the SRAM.
This transpose memory design using SRAM scales very well for lower through-
puts. A 2-pixel/cycle transpose memory would need two banks each with 512 entries
(16-bit/entry). For higher throughputs, one needs more banks each with fewer
entries. Such short SRAM banks have a larger area overhead of sense-amplifiers
and other read-out circuitry. For throughputs higher than 32-pixel/cycle, register
based transpose memory [
23
] is more area-efficient.
10.4.3
Inverse DCT Engine
The IDCT engine can be optimized by observing that the N-pt IDCT matrix has at
most N unique coefficients differing only in sign. This is also true of the matrices
obtained by even-odd decomposition of the IDCT matrix, such as the 16
16 matrix
of the 32-pt IDCT. This 256-element matrix contains 15 unique numbers: 90, 88, 85,
82, 78, 73, 67, 61, 54, 46, 38, 31, 22, 13, 4 (and their additive inverses). The matrix
is multiplied with the odd-indexed coefficients in the 32-pt IDCT. In a 4-pixel/cycle