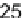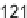Graphics Reference
In-Depth Information
Fig. 10.6
32 TU to four SRAM banks for transpose operation. The
color
of each
pixel denotes the bank and the
number
denotes the bank address
Mapping a 32
with the necessary read circuit for the transpose operation takes up a lot of area
(125 kgate) when implemented with registers and multiplexers. Also, the register-
based transpose memory has a much higher throughput than required. SRAMs are
more area-efficient than registers and have a lower throughput, which makes them
a good choice for an optimized implementation. The main disadvantage of SRAMs
is that they are less flexible than registers. A register array allows reading and
writing to arbitrary number of bits at arbitrary locations, although very complicated
read(write) patterns would lead to a large output(input) mux size. The SRAM read
or write operation is limited by the bit-width of its port. A single-port SRAM allows
only one operation, read or write, every cycle. Adding extra ports is possible at the
expense of significant area increase.
It is possible to implement the 4-pixel/cycle transpose memory using four single-
port banks of 4,096 bits each with a port-width of 1 pixel. The pixels in a 32
32 TU
are mapped to locations in the four banks as shown in Fig.
10.6
. By ensuring that
four adjacent pixels in any row or column sit in different SRAM banks, it is possible
to write along columns and read along rows by supplying different addresses to the
four banks.
After a 32-pt column transform is computed, the result is saved in a temporary
register and is written to the transpose SRAM over eight cycles. At the same time,
the 1-D transform module processes the next column. This is shown in cycles 0-7
in Fig.
10.7
a, where the result of column 30 is written to the SRAM while the 1-D
transform module works on column 31. However, when the last column in a TU is