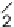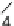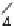Graphics Reference
In-Depth Information
a
b
Fig. 10.5
Possible high-level architectures for inverse transform with 2 pixel/cycle throughput.
Bus-widths are in pixels. (
a
) Separate row and column transform stages. (
b
) 1-D transform stage
shared by row and column transform
read and one write port and hold two TUs—in the worst case, two 32
32 TUs.
Also, the two TUs would take different number of cycles to finish processing. For
example, if a 8
8 TU follows a 16
16 TU, the column transform must remain idle
after processing the smaller TU as it waits for the row transform to finish the larger
one. It can begin processing the next TU but managing several TUs in the pipeline
at the same time will require complex control logic to avoid stalls.
With these considerations, the second architecture, shown in Fig.
10.5
bis
preferred. This uses a single 4 pixel/cycle 1-D transform for both row and column
transform to achieve the desired 2 pixel/cycle 2-D transform throughput. The 1-D
transform works on a single TU at a time, processing all the columns first and then
all the rows. Hence, the transpose memory needs to hold only one TU and can be
implemented with a single port SRAM since row and column transforms do not
occur concurrently.
10.4.2
Transpose Memory
The transform block uses a 16-bit precision input for both row and column
transforms. The transpose memory must be sized for 32
32 TU which means a
total size of 16
32
32
D
16:4 kbit. In comparison, H.264/AVC decoder designs
require a much smaller transpose memory—16
8
8
D
1 kbit. A 16.4 kbit memory