Database Reference
In-Depth Information
model and that the following segments of information should be smaller to
indicate a segment of information that is not fully compatible or totally
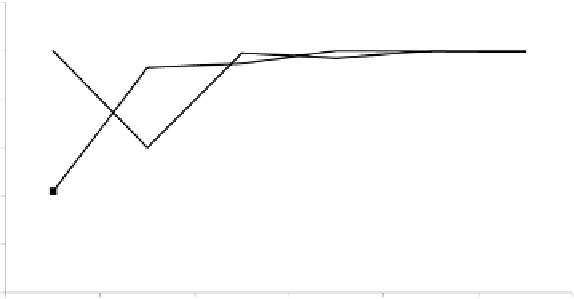
incompatible with the base data-mining model. Figure 4.5 depicts the outcome of
implementing the change-detection methodology on these segments of data.
120%
100.00%
100.00%
100.00%
99.00%
97.00%
100%
100.00%
99.87%
99.71%
94.74%
93.14%
80%
60.00%
60%
40%
41.77%
20%
0%
2
3
4
5
6
7
Segment
CD XP
Fig. 4.5.
Implementation of CD and XP on trial number 2 in 'Stock' Database.
Our objective is to find the best suitable segmentation. Therefore, we need to
evaluate which of the three trials produced a “better” segmentation, based on the
outcomes of the change-detection methodology. When evaluating these outcomes
we mainly consider the parameter CD, which describes the “level of fitness” of a
new data segment to previously built classification models of data mining.
Based on the major outcomes of the change-detection methodology, an
evaluation of the best segmentation is provided by the accumulated parameters of
the model detection. The summary is presented in Fig. 4.6.
In Fig. 4.6 a statistical analysis of the CD parameter in all three trials is
described. The analysis describes three possible segmentations for the given data
stream. Deciding what is the best possible segmentation is the user's choice. It is
possible to use one or a combination of the statistics. The possible statistical
parameters, which are used in this set of experiments, are:
1. Deciding on a better segmentation, based on the range of
P
over
all segments of a data stream. Range is calculated by the following equation:
))
1
value
CD
(
)
. A higher range denotes a
Range
Max
(
P
(
CD
))
Min
(
P
(
CD
value
value
better segmentation.
2. Deciding on a better segmentation, based on the standard deviation of
)
P
over all segments of a data stream. Greater standard deviation
denotes a better segmentation.
1
value
CD
(












Search WWH ::

Custom Search