Database Reference
In-Depth Information
level-of-abstraction in the database. The multiple level-of-abstraction information is
downloaded, and updated from the data mining server using HTTP (Hyper-Text
Transfer Protocol). In addition, this system can manage the user's access patterns
providing the user used the service for a certain period. By using this information, the
speech interactive agent can speak to the user when the system is first switched on at
the start of the day, and the scheduled job should be executed. This information is
also managed in the database by using multiple level-of-abstraction.
2.2 Speech Interactive Agent
Conversation is one of the most important factors that facilitate dynamic knowledge
interaction. People can have a conversation with a conversational agent that talks with
people by using the eASR and eTTS [19] as a combined unit. The speech interaction
agent, as a conversational agent [10][16], carries out command and control tasks while
interacting with the driver according to the given scenarios on the car navigation system.
As a problem-solving paradigm, the fusion process model using the functional
evaluation stage is employed [12]. Although the car navigation system is determinis-
tic, the use of multiple input sensors makes the system complex to cope with various
situations. The proposed speech agent is decomposed into three separate processes;
composition process of sensory sources, speech signal processing process and deci-
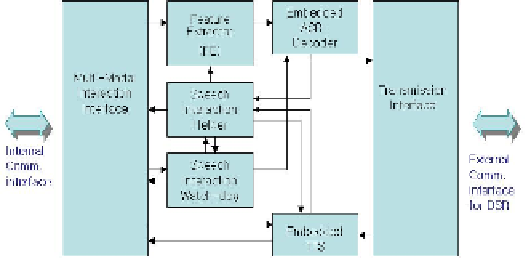
sion-making process. As shown in Figure 2, the composition process of sensory
sources plays a role in combining input requests and guiding the next-step. The
speech signal processing process provides a means of speech interaction using speech
recognition and text-to-speech functions. The decision-making process provides a
user-friendly interfacing mode using a speech interaction helper function as well as a
self-diagnosis function using a speech interaction watch-dog module.
Fig. 2.
Speech Interactive Agent (SIA) block diagram
The speech recognition system is classified into the embedded ASR and distributed
speech recognition (DSR) system that is used via the wireless network, using a
CDMA 2000 terminal. Thus, the feature extractor based on ETSI v1.1.2 has the
front-end role of passing the mel-cepstral features to eASR or DSR according to the
scenarios without communicating between the speech agent and the application proc-
ess. The eTTS utters the information when the event is requested by the user and
application programs. The ''speech interaction helper'' provides helper scenarios to
Search WWH ::

Custom Search