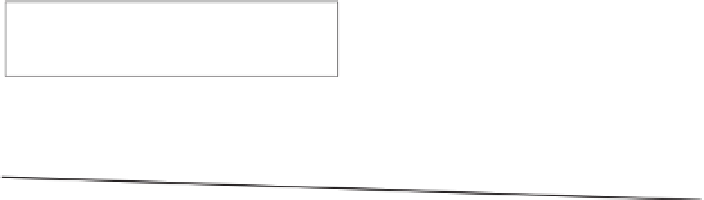Agriculture Reference
In-Depth Information
Where
Y
is a vector of observation;
f
is some
unknown function or set of functions;
X
is a
matrix of input variables (observed);
b
is a
vector of parameters to the function
f
; and
e
is a vector of errors.
Stochasticity can enter Eqn 5.4 at four
different locations:
f
,
X
,
b
and
e
.
The vector of errors,
e
, is a random vari-
able that aggregates many sources of errors.
Measurement errors on the
Y
appear in
e
.
This component has traditionally been la-
belled as pure error (Draper and Smith, 1998).
But
e
also contains some of the errors asso-
ciated with having an incorrect model, the
lack-of-fit component (Draper and Smith,
1998). Often, experimental data do not allow
the partitioning of
e
into pure error and lack-
of-fit. This partitioning requires replicated
observation at identical levels of all
X
values.
This can easily be done when an experiment
is designed for the specific purpose of model
parameterization. In many instances, how-
ever, models are parameterized using litera-
ture data. In such instances, the partitioning
of
e
into its two basic components is at best
difficult and often impossible. This is unfor-
tunate because the true error represents the
variance from measurement errors in the
Y
.
This true error represents a limit of accuracy
of any potential model. The lack-of-fit com-
ponent, however, represents the uncertainty
regarding
f
. It is in essence a measure of func-
tional adequacy.
Figure 5.2
shows a residual
plot of non-ammonia-non-microbial nitro-
gen flow through the duodenum (NANMN)
for the NRC (2001) dairy cattle model. Over
the whole range of predictions, the average
residual error (observed minus predicted
values) is very close to zero, but the spread
of the errors is quite large. In fact, the standard
error (i.e. the standard deviation of the re-
sidual error) amounts to approximately 40%
of the average NANMN prediction (St-Pierre,
2001). This can result from large errors in
the measurements themselves (pure error)
or from an inadequate model that doesn't
account for a sufficient number of variables
that affect NANMN (lack-of-fit). If pure error
is the predominant factor explaining the
large standard error, then little gain can be
made in model accuracy until the precision
of the measurements is improved. If, how-
ever, lack-of-fit dominates the error, then
the model is grossly inadequate.
The uncertainty of the parameters
b
is
the second source of stochasticity in Eqn 5.4.
This uncertainty can be expressed statistic-
ally using either a frequentist or a Bayesian
framework. For a frequentist, the
b
are fixed
parameters and thus, without errors. The
b
,
however, are unknown. Their estimates, con-
ventionally known as
B
, are random variables.
250
Y
= -0.2 (± 3.9) - 0.13 (± 0.05) (
X
- 211)
s
= 65.0,
R
2
= 0.02,
P
= 0.02
200
150
100
50
0
-
50
-
100
-
150
-
200
-
250
0
100
200
300
400
Predicted NANMN (g/day)
Fig. 5.2.
Plot of observed minus predicted non-ammonia-non-microbial nitrogen flow to the duodenum
(NANMN) vs predicted NANMN. (Data are from NRC, 2001, figure
5-7.)