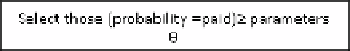Information Technology Reference
In-Depth Information
Fig. 1.
Bayesian Network Algorithm
1.
Take the training data
D
as input.
2.
Compute the conditional mutual information[21] by
p
(
x
,
x
|
y
)
i
j
k
I
(
X
,
X
|
Y
)
=
P
(
x
,
x
,
y
)
×
log(
)
i
j
i
j
k
p
(
x
|
y
)
p
(
x
|
y
)
x
,
x
,
y
i
k
j
k
(1)
i
j
k
In probability theory and information theory, the mutual information of two random
variables is a quantity that measures the mutual dependence of the two random va-
riables. Learning a tree-like network structure over D by using the structure learning
algorithm outlined below.
3.
Using Prim's algorithm (Prim, 1957) to construct a maximum weighted spanning
tree with the weight of an edge connecting
.
4.
Transform the resulting undirected tree to directed one by choosing
X
1
as a root node
and setting the direction of all edges to be outward from it.
5.
Add
Y
as a parent of every
X
i
where
X
to
X
by
I
(
X
,
X
|
Y
)
i
j
1
≤
i
≤
n
.