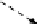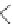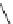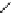Information Technology Reference
In-Depth Information
0
3
Idx
Prefix
NextHop
N
1
N
2
P
4
P
1
P
1
P
2
0 *
1 *
P
3
15
P
3
N
3
16
1 0 *
P
5
P
4
N
4
21
23
27
31
0 0 0 *
P
5
1 0 1 0 1 *
N
2
P
6
P
2
P
6
N
2
1 1 0 1 1 *
(a)
(b)
P
4
000
00
:
000
11
:
0
0100
:
direct table
P
1
P
3
P
P
3
P
P
2
0
1111
:
10
000
:
10
100
:
10101
:
10
110
:
10
111
:
10
000
:
P
3
(10*)
P
7
(1*
N
5
)
10
111
:
P
2
1
1000
:
1
1010
:
11011
:
1
1100:
1
1111:
1
1111:
(c)
Fig. 1.
(a) FIB. (b) A sample of GALE's direct table. Deleting
P
3
(10
∗
)fromitand
then inserting
P
7
(1
∗,N
5
)intoitmustbeprocessedinorder.(c)Transformingprefixes
into segments. To simplify examples, we suppose the focused maximum prefix length
is 5 (which is 24 in practice).
Fortunately, some GPU-based software routers [8-10] have been proposed to
provide both high throughput and high scalability. However, with major focus on
the entire framework design, they all treat the routing table as static and thus fail
in dealing with update overhead. In view of this, J. Zhao et al. [11] presented a
GPU-Accelerated Lookup Engine (GALE), which provides both fast lookup and
the solution to route updates. Due to its update mechanism, a update request,
after being used to update a trie, is mapped into a range of unit modifications
toward a direct table stored on the GPU. However, different updates may be
mapped to the same unit. So, even with a careful length checking, breaking their
order may also lead to incorrect updates (as shown in Fig. 1(c)). Accordingly, in
GALE, not all updates can be processed in parallel, which obstructs it to benefit
enough from GPU's parallelism.
1.2 Our Approach and Key Contributions
In this paper, we first implement the TBL24 of DIR-24-8 scheme [12] on the
GPU, just like GALE, to enable O(1) lookup. Then, instead of using a trie, we
present a novel tree-like structure, Threaded Segment Tree (TST), to process