Information Technology Reference
In-Depth Information
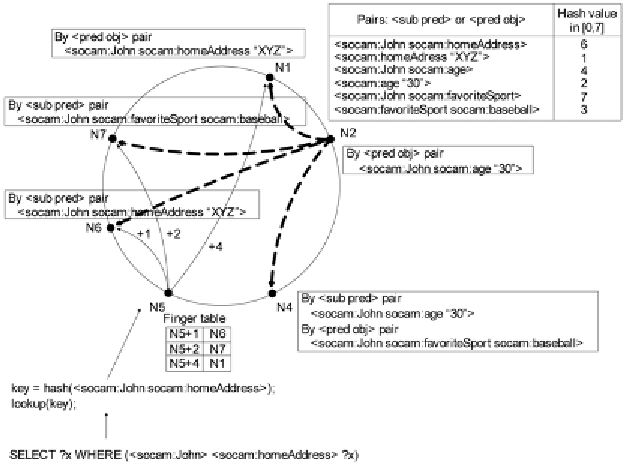
Figure 4. An example of 3-bit Chord identifier space of 6 nodes (could hold up to 8 nodes) for the il-
lustrating of storing data triples and query routing
tate efficient context query, we build distributed
indices for each data triple. Each data triple is in
the form of subject, predicate, and object. Since
the predicate of the triple is always given in a
context query, we store each data triple two times
in Chord. We apply the hash function to the
<sub
pred>
and
<pred obj>
pairs to generate the keys
for storing each data triple. Each data triple will
be stored at the successor nodes of the hashed
key values of
<sub pred>
and
<pred obj>
pairs.
We define the
Store
procedure to perform the
above storing process for each data triple. Figure
4 illustrates the process that node
N2
stores the
following data triples in a 3-bit Chord identifier
space of 6 nodes.
To register the indices of data corresponding
to the minor semantic cluster(s), a node first sends
a
Register
message to a random node in each of
its minor semantic clusters, and then it follows
the same procedure as above to store the indices.
QUERY ROUTING
The query routing process involves two steps:
inter-cluster routing and intra-cluster routing. A
context query will be first forwarded to the ap-
propriate semantic cluster and routed to destina-
tion peers in the lower-tier network. When a node
receives a context query, the destination semantic
cluster can be extracted from the query using the
ontology-based semantic mapping technique (de-
scribed in Section 2.2). First, we obtain the search
key by hashing the destination semantic cluster.
We then compare the search key with the most
significant
m
-bits of its neighbors' identifiers, and
forward the query to the closest neighboring node.
<socam:John socam:homeAddress “XYZ”>
<socam:John socam:age “30”>
<socam:John socam:favoriteSport
socam:baseball>
Search WWH ::

Custom Search