Information Technology Reference
In-Depth Information
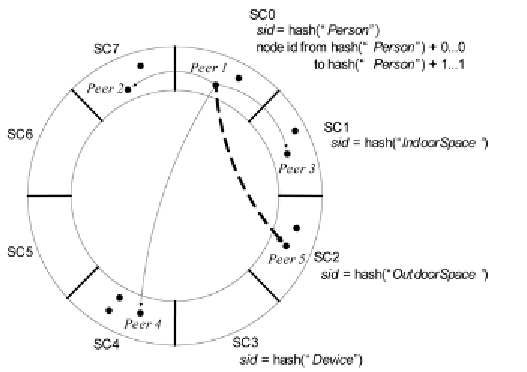
Figure 3. The construction of the upper-tier network (note: the sign “+” represents appending)
range contacts); and each node knows a small
number of randomly chosen distant nodes (called
long range contacts), with probability proportional
to
1/d
where
d
is the distance (Kleinberg, 2000).
The constant number of contacts and small aver-
age path length serve as the motivation for us to
build the upper-tier network using the small world
network model.
To construct the upper-tier network, each node
maintains a set of short range contacts to a peer in
its neighboring semantic clusters and a number of
long range contacts. As shown in Figure 3,
Peer
1
maintains
Peer 2
as its left short range contact
and
Peer 3
as its right short range contact; and
that results all the semantic clusters are linked
linearly in a ring fashion. The long range con-
tacts are obtained by randomly choosing a node
in the upper-tier based on a distribution function
with its probability proportional to
1/d
, where
d
is the semantic distance (e.g., can be represented
as Euclidean distance). The long range contacts
aim at providing shortcuts to reach other semantic
clusters quickly. Via short range and long range
contacts, search in the upper-tier network can be
guided greedily by comparing
sids
of the desti-
nation and the traversed nodes. In addition, if a
peer has context data corresponding to its minor
semantic clusters, it needs to register the indices
of these data to a random node in each of its minor
semantic clusters, e.g.,
Peer 1
registers its data
indices to a random node -
Peer 5
in
SC2
since
it has data corresponding to semantic cluster -
OutdoorSpace
. This ensures that a context query
is able to reach all the relevant nodes that store the
keys responsible for the query. The registration
process of data indices is similar to the storing
process of data triples in the lower-tier network,
and it will be described in the next section.
THE LOWER-TIER NETWORK
In the lower-tier network, peers in each semantic
cluster are organized as Chord for storing data
triples and routing context queries. This approach
divides the one-dimensional Chord identifier space
into multiple Chord identifier spaces. The number
of neighbors maintained per node is logarithmic
to the number of nodes in its semantic cluster.
Hence, the maintenance cost can be reduced as
compared to the original Chord.
A peer is organized into Chord based on the
randomly chosen node identifier by applying the
SHA1 hash function to its IP address. To facili-
Search WWH ::

Custom Search