Information Technology Reference
In-Depth Information
tion of
t
can have an impact on the performance
of prefetching. We will analyze this parameter in
the simulations.
Besides of the memory nodes and user nodes,
we also exploit the manager nodes, which often
have idle CPU cycles and less churn, to collect
and merge the trace items from each memory node
and compose a trace library from the accumulated
trace items. The manager nodes should also dis-
patch the trace library to new memory nodes for
prefetching. There is a maximum number for the
trace items in a trace library, denoted as
M
. It is
related with the system performance. Indeed, the
larger
M
means more user patterns and more ac-
curate results in the prefetching algorithm, while
the larger
M
also needs more memory space to
hold the trace library and more transmission cost
between manager nodes and the memory nodes.
We will evaluate the impact of
M
later.
quence β =
b b
b
m
, denoted as α
⊆ ,
iff
,
, ...,
1
2
there exist integers 1
≤ < < < ≤
i
i
...
i
m
,
1
2
n
such that
a
, ...,
. A se-
quence can be appended to another sequence
using a concatenation operator '+'. For example,
α
= ,
a
b
i
=
b
a
=
b
1
2
i
n
i
n
1
2
, , ..., , , , ...,
. The first
occurring position of an item
a
in a sequence
S
is
denoted as
first S a
+ =
a a
a b b
b
1
2
n
1
2
m
( , )
, thus
first
( ,
β
b
)
=
n
n
(
b
, , ...,
). A trace library
L
is
an ordered set consisting of multiple sequences,
that is,
L
≠
b b
≠
b
b
≠
b
1
n
2
n
n
−
1
n
= S
1
, , ...,
.
For a given sequence
S
, if there exists a trace
library
L
S
S
n
(
)
∈
1,
,
then we say that
L
supports
S
, and the support of
S
in trace library
L
is the number of
S
i
in
L
which
satisfies
S S
Í . The problem of mining prefetch-
ing sequences can be described as follows.
For a given access
o
c
, search
S
, and
S
= S
1
,
S
, ...,
S
n
⊆
S i
n
2
i
=
,
o o o
,
, ...,
o
c
1
2
n
with the maximum support in the trace library,
where
length
( )
³ 2 .
S
is called the prefetching
list. The memory node obtains the prefetching list
S
and sequentially pushes pages in the list to the
user node, when the latter performs a “get page”
operation with an access
o
c
.
According to the definition ofα ⊆ , the com-
mon items in aandbis not necessary to be con-
secutive. Supposing
S
PREFETCHING ALGORITHM
The goal of the prefetching algorithm is to pre-
dict the most likely pages of future requests that
start with the current request issued by the user
node. The memory node needs to determine those
pages based on the user patterns derived from
the trace library and other necessary parameters,
such as the maximum prefetching buffer length
of the user node,
k
. In order to reduce the network
communication cost, we want the predicted and
prefetched memory pages to have the highest
probability to be used by the user node. In fact,
selecting proper pages is a data mining problem,
which can be defined as follows.
Let
o o
= A
1
, , , , ,
,
B A B A B
1
1
2
2
3
3
= A
1
, , , then we have
S
2
Í . This
definition solves the problem mentioned in last
section.
In fact, the background of the prefetching
algorithm is inspired by the traditional sequential
pattern mining (Agrawal,
et al.
, 1995, 1996). Al-
though the there exist similarities, the problem is
quite different. Firstly, an item in sequential pat-
tern mining can be composed by several numbers,
while for prefetching it is just a single number
that indicates the block identification. Moreover,
the output of sequential pattern mining is the se-
quence whose support is higher than a threshold
S
A A
2
2
3
1
, , ...
{ }
be a set of all possible items,
where each item is a recorded access. A sequence
S
, which can be denoted as
S
o
n
=
1
, , ...,
,
is an ordered list of items. The number of items
in sequence
S
, denoted as
length
(
S
). A sequence
α =
a a
o o
o
n
,
, ...,
a
n
is contained in another se-
1
2
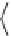

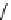

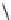












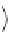



Search WWH ::

Custom Search