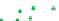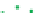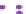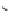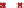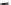Geoscience Reference
In-Depth Information
Partially labeled data
Complete linkage clustering
Predicted labeling
70
70
70
60
60
60
50
50
50
40
40
40
80
90
100
110
80
90
100
110
80
90
100
110
weight (lbs.)
weight (lbs.)
weight (lbs.)
Figure 3.6:
Cluster-then-label results using complete linkage hierarchical agglomerative clustering. This
clustering result does not match the true labeling of the data.
meant to highlight the sensitivity of semi-supervised learning to its underlying assumptions—in this
case, that the clusters coincide with decision boundaries. If this assumption is incorrect, the results
can be poor.
This chapter introduced mixture models and the expectation maximization (EM) algorithm
for semi-supervised learning. We also reviewed some of the common issues faced when using gener-
ative models. Finally, we presented a non-probabilistic, cluster-then-label approach using the same
intuition behind mixture models: the unlabeled data helps identify clusters in the input space that
correspond to each class. In the next chapter, we turn to a different semi-supervised learning approach
known as co-training, which uses a very different intuition involving multiple feature representations
of instances.
BIBLIOGRAPHICAL NOTES
The theoretical value of labeled and unlabeled data in the context of parametric mixture models has
been analyzed as early as in [
30
,
142
]. Under certain conditions [
62
,
161
], theoretic analysis also
justifies the Cluster-then-Label procedure [
59
,
52
,
74
]. It has also been noted that if the mixture
model assumption is wrong, unlabeled data can in fact hurt performance [
48
].
In a seminal empirical paper [
135
], Nigam
et al.
applied mixture of multinomial distributions
for semi-supervised learning to the task of text document categorization. Since then, similar algo-
rithms have been successfully applied to other tasks [
13
,
66
,
67
]. Some variations, which use more
than one mixture components per class, or down-weight unlabeled data relative to labeled data, can
be found in [
28
,
43
,
128
,
135
,
152
].
The EM algorithm was originally described in [
60
]. More recent interpretations can be found
in, e.g., [
19
]. Some discussions on identifiability in the context of semi-supervised learning can be
found in [
43
,
125
,
142
]. Local optima issues can be addressed by smart choice of starting point using
active learning [
133
].