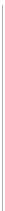Geoscience Reference
In-Depth Information
to the currently labeled data. The selected instance is then assigned the label of its nearest neighbor
and inserted into
L
as if it were truly labeled data. The process repeats until all instances have been
added to
L
.
We now return to the data featuring the 100 little green aliens. Suppose you only met one
male and one female alien face-to-face (i.e., labeled data), but you have unlabeled data for the
weight and height of 98 others. You would like to classify all the aliens by gender, so you apply
propagating 1-nearest-neighbor. Figure 2.3 illustrates the results after three particular iterations, as
well as the final labeling of all instances. Note that the original labeled instances appear as large
symbols, unlabeled instances as green dots, and instances labeled by the algorithm as small symbols.
The figure illustrates the way the labels propagate to neighbors, expanding the sets of positive and
negative instances until all instances are labeled. This approach works remarkably well and recovers
the true labels exactly as they appear in Figure 1.3(a). This is because the model assumption—that
the classes form well-separated clusters—is true for this data set.
70
70
65
65
60
60
55
55
50
50
45
45
40
40
80
90
100
110
80
90
100
110
weight (lbs.)
weight (lbs.)
(a) Iteration 1
(b) Iteration 25
70
70
65
65
60
60
55
55
50
50
45
45
40
40
80
90
100
110
80
90
100
110
weight (lbs.)
weight (lbs.)
(c) Iteration 74
(d) Final labeling of all instances
Figure 2.3:
Propagating 1-nearest-neighbor applied to the 100-little-green-alien data.
We now modify this data by introducing a single outlier that falls directly between the two
classes. An outlier is an instance that appears unreasonably far from the rest of the data. In this case,
the instance is far from the center of any of the clusters. As shown in Figure 2.4, this outlier breaks