Geoscience Reference
In-Depth Information
film
⇒
f ih_n uh_gl_n m
be all
⇒
bcl b iy iy_tr ao_tr ao l_dl
Accurate transcription by human expert annotators can be extremely time consuming: it took
as long as 400 hours to transcribe 1 hour of speech at the phonetic level for the Switch-
board telephone conversational speech data [
71
] (recordings of randomly paired participants
discussing various topics such as social, economic, political, and environmental issues).
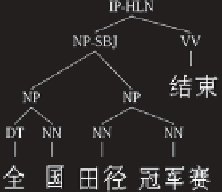
In natural language parsing, an instance
x
is a sentence, and the label
y
is the corresponding
parse tree. An example parse tree for the Chinese sentence “The National Track and Field
Championship has finished.” is shown below.
The training data, consisting of (sentence, parse tree) pairs, is known as a treebank. Tree-
banks are time consuming to construct, and require the expertise of linguists: For a mere
4000 sentences in the Penn Chinese Treebank, experts took two years to manually create the
corresponding parse trees.
In spam filtering, an instance
x
is an email, and the label
y
is the user's judgment (spam or
ham). In this situation, the bottleneck is an average user's patience to label a large number of
emails.
In video surveillance, an instance
x
is a video frame, and the label
y
is the identity of the object
in the video. Manually labeling the objects in a large number of surveillance video frames is
tedious and time consuming.
In protein 3D structure prediction, an instance
x
is a DNA sequence, and the label
y
is
the 3D protein folding structure. It can take months of expensive laboratory work by expert
crystallographers to identify the 3D structure of a single protein.
While labeled data
(
x
,y)
is difficult to obtain in these domains, unlabeled data
x
is available
in large quantity and easy to collect: speech utterances can be recorded from radio broadcasts; text
sentences can be crawled from the World Wide Web; emails are sitting on the mail server; surveillance
cameras run 24 hours a day; and DNA sequences of proteins are readily available from gene databases.
However, traditional supervised learning methods cannot use unlabeled data in training classifiers.