Geoscience Reference
In-Depth Information
3.3.4
Definition of a Distance Measure for
the High-Dimensional Data
In order to project the high-dimensional data onto a space which can be visualized or
to identify clusters in the data, a meaningful (dis-) similarity measure (data distance)
must be defined. The distance measure must be such that similar data are close and
differing data distant. Each variable should be well captured by this measure. Two
variables with a high correlation represent basically the same information. Thus, if
both variables are included in a data distance, the same information is weighted by a
factor of 2. One simple approach to address this effect is to remove highly correlated
data from the definition of a meaningful data distance.
For the UD data, it makes sense to include only the four variables
OpenSpaceMeshSize, BuildingArea, SealedSurface, and ProtectedAreas as the
other variables are highly correlated to this subset, so that their information is
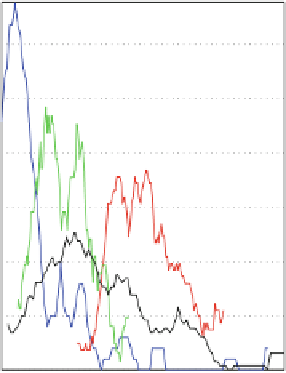
already contained in the selected variables. Comparison is of the transformed
variables. Otherwise, the differences between two data points within a variable
would not be comparable (cf. Fig.
3.9
). In order to adjust the scaling for the data, all
data was rescaled to percent.
0.022
0.06
0.02
0.018
0.05
0.016
0.014
0.04
0.012
0.03
0.01
0.008
0.02
0.006
0.01
0.004
0.002
0
20
40
60
80
20
40
60
80
Selected UD data
Transformed UD data
Fig. 3.9
Comparison of the distributions of original (
left
) and transformed variables (
right
).
Blue = OpenSpaceMeshSize, red = BuildingArea, green = SealedSurfaces, black = ProtectedAreas































































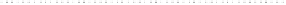


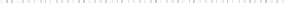













Search WWH ::

Custom Search