Database Reference
In-Depth Information
based on other fields in the various files. Both primary indexes and secondary
indexes serve well in improving performance.
In addition to indexing, a few other options are available to enhance data access
performance and to improve storage management. We will now explore some of
these other improvement techniques. Some of these techniques may readily apply
to your particular database system. A few others may have universal applicability.
Study the techniques as we discuss them and try to determine their applicability to
your environment.
Clustering
Consider two relational tables common in most database environments—the
ORDER table and the ORDER DETAIL table. Typically, the details of each order
are retrieved along with order data. Most of the typical data access to order infor-
mation requires retrieval of an order row from the ORDER table together with
rows from the ORDER DETAIL table for that order. Let us see if we can improve
data access performance in such situations when rows from two tables are usually
retrieved together in one transaction. How can we do this?
Instead of placing the rows from the ORDER table and the rows from the
ORDER DETAIL table in two separate files, what if we place the rows from
both tables as records in one file? Furthermore, what if we interleave the order
detail records with the corresponding order records in this single file? Then, as the
records in the file are allocated to storage, it is most likely that an order and its
details will reside on one block. What is the big advantage of this arrangement? In
one I/O operation, order and corresponding order detail records can be retrieved.
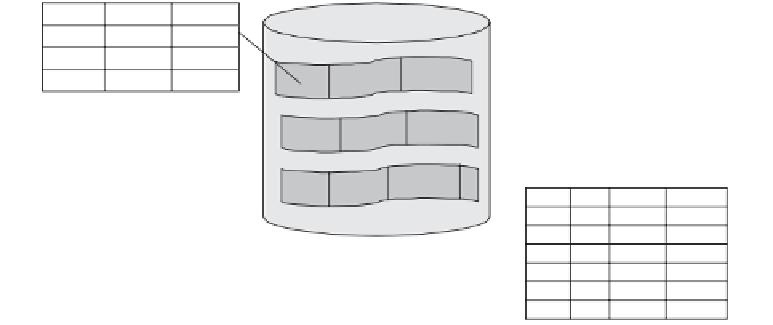
This principle of interleaving related records from two tables in one file is called
clustering. Figure 12-19 illustrates clustering of ORDER and ORDER DETAIL
records.
If your DBMS supports data clustering, you can utilize this significant feature to
improve performance. To create a cluster, you need to identify the tables whose
rows must be clustered and the key columns that link those tables. The DBMS will
then store and retrieve related records from the same cluster.
OrdNo
12
23
34
OrdDte
1-Mar
15-Mar
22-Mar
OrdAmt
250.00
300.00
175.00
OrdNo
12
12
12
23
23
34
DtlNO
1
2
3
1
2
1
Product
ABC
XYZ
EFG
DEF
ABC
Quantity
10
15
20
15
10
25
EFG
Figure 12-19
Data clustering.


Search WWH ::

Custom Search