Image Processing Reference
In-Depth Information
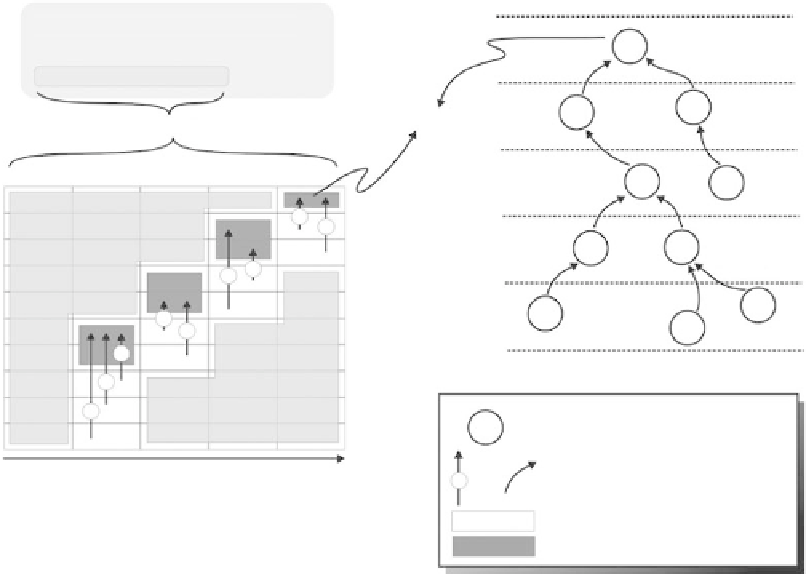
Hop count level = 0
Query injected into the network:
A
Select count(*) from sensors
2
7
Hop count level = 1
Sample period 10 s
C
B
Count = 10
Epoch
6
Hop count level = 2
1
Interval 5
Interval 4
Interval 3
Interval 2
Interval 1
E
D
A
2
3
Hop count level = 3
7
B
2
Nodes sleeping
F
G
C
D
Hop count level = 4
1
1
6
1
1
E
I
H
3
J
F
2
Hop count level = 5
1
G
H
Communication topology
1
Nodes sleeping
I
J
KEY
1
G
Node with ID “G”
Partial aggregate
message with count
Time
1
or
2
Radio in transmit mode
Radio in listen mode
FIGURE .
Aggregation operation using interval-based communication scheduling.
extended to perform more complex tasks such as vehicle tracking and isobar mapping []. TinyDB
depends on MAC-level acknowledgments and runs a tree-maintenance algorithm continuously in
order to ensure that communication between nodes can continue seamlessly at all times.
The optimizations found in Cougar, TinyDB, and TiNA are suitable for mainly snapshot, range
queries where the user is interested in aggregated results, e.g., MIN, MAX, SUM, AVG, etc. On the
other hand, it is possible for these mechanisms to acquire raw data over extended periods of time, e.g.,
in all these approaches, the user could simply inject a
SELECT *
SQL-like query into the network.
However, none of the mechanisms perform any optimizations to efficiently gather raw data over
extended time periods.
The distributed and self-organizing scheduling algorithm (DOSA) for energy-efficient data aggre-
gation [] scheme helps reduce transmissions by taking advantage of the spatial correlations that
might exist between neighboring sensor nodes. he authors present a self-stabilizing scheduling algo-
rithm that decides when certain nodes in the network should act as correlating nodes. Correlating
nodes are in charge of identifying any correlations that may exist between their own readings and
readings of nodes in their one-hop neighborhood. If correlations exist, a correlating node transmits
this correlation information to the sink and also its own sensor readings. he sink node then uses the
correlating node's own reading and combines the received correlation information to compute the
readings of the correlating node's one-hop neighbors. The authors not only present some theoreti-
cal bounds on the energy consumption but also implement the algorithm on actual sensor nodes to
demonstrate that how it functions in real-life. However, due to its cross-layered design, the a node's
scheduling scheme may be adversely affected if has a poor link quality with its one-hop neighbors.
While the majority of the literature in this category focuses on utilizing diferent strategies to ensure
energy-efficient operation, none of the authors investigate the performance of unreliable message