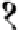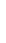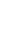Information Technology Reference
In-Depth Information
Table 3.
Classification results
Dataset
% correct
% incorrect
% reject
DS1
96.23
2.14
1.63
DS2
95.68
2.44
1.88
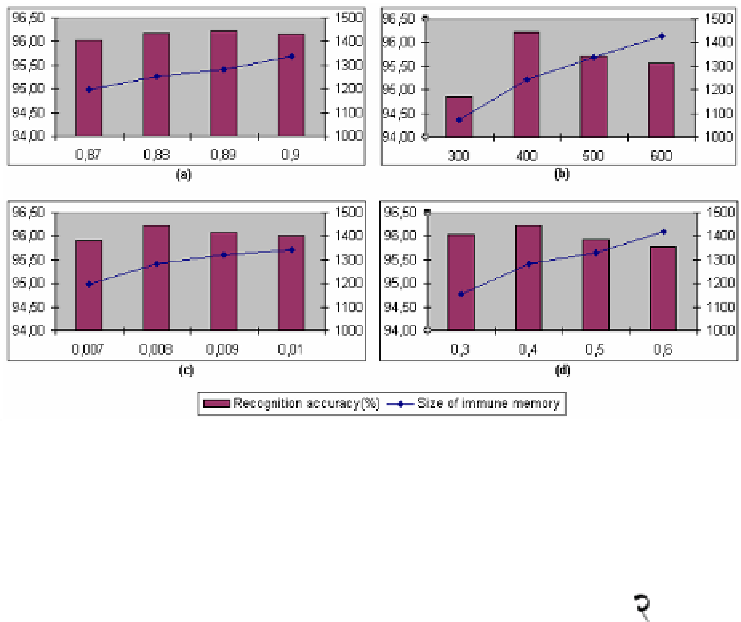
Fig. 3.
Effect of different parameters on recognition accuracy and size of immune memory: (a)
stimulation threshold (refer equation (3)), (b) number of resources used for resource limitation,
(c) Mutation rate (refer Algorithm-II), and (d) Affinity threshold scalar,
α
as used in Algo-
rithm-III
Fig. 5 presents the class-wise classification rates. Recognition of the digit '0' attains
highest recogn
ition
score in both scripts. On the other hand, samples of (digit '2')
in Hindi and (digit '9') in Bengali result in the lowest classification rates as
89.32% and 90.52%, respectively. Study of the confusion matrix identifies several
similar-shaped character pairs. For
exam
ple, many sa
mple
s from (digit '1') and
(digit '2') in Hindi dataset and from (digit '1') and (digit '9') in Bengali dataset
resulted in confusion during classification. Some post-processing can be employed to
discriminate such confusion pairs. In this context, a previous study [5] reported prom-
ising ability of an AIS-based approach for discrimination of similar-shaped character
pairs. The same approach can also be employed here to further improve the classifica-
tion accuracy. Such multi-level recognition scheme is considered as a future extension
of the present study.