Hardware Reference
In-Depth Information
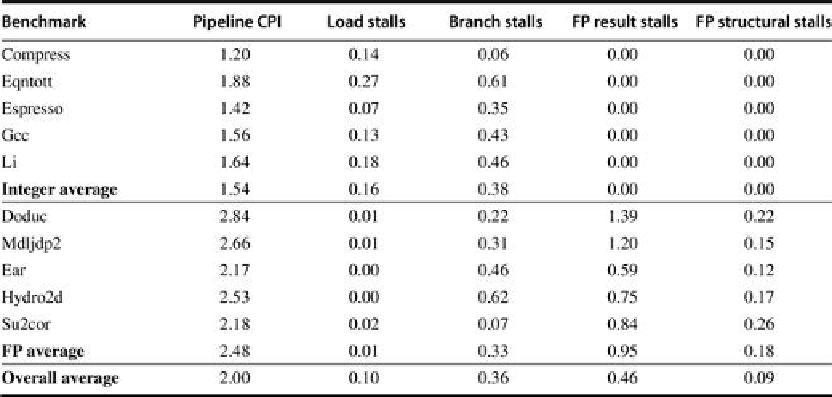
FIGURE C.53
The total pipeline CPI and the contributions of the four major sources of
stalls are shown
. The major contributors are FP result stalls (both for branches and for FP in-
puts) and branch stalls, with loads and FP structural stalls adding less.
From the data in
Figures C.52
and
C.53
,
we can see the penalty of the deeper pipelining.
The R4000's pipeline has much longer branch delays than the classic five-stage pipeline. The
longer branch delay substantially increases the cycles spent on branches, especially for the in-
teger programs with a higher branch frequency. An interesting effect for the FP programs is
that the latency of the FP functional units leads to more result stalls than the structural haz-
ards, which arise both from the initiation interval limitations and from conflicts for functional
units from different FP instructions. Thus, reducing the latency of FP operations should be the
irst target, rather than more pipelining or replication of the functional units. Of course, redu-
cing the latency would probably increase the structural stalls, since many potential structural
stalls are hidden behind data hazards.
C.7 Crosscutting Issues
RISC Instruction Sets And Efficiency Of Pipelining
We have already discussed the advantages of instruction set simplicity in building pipelines.
Simple instruction sets offer another advantage: They make it easier to schedule code to
achieve efficiency of execution in a pipeline. To see this, consider a simple example: Suppose
we need to add two values in memory and store the result back to memory. In some soph-
isticated instruction sets this will take only a single instruction; in others, it will take two or
three. A typical RISC architecture would require four instructions (two loads, an add, and a
store). These instructions cannot be scheduled sequentially in most pipelines without inter-
vening stalls.
With a RISC instruction set, the individual operations are separate instructions and may be
individually scheduled either by the compiler (using the techniques we discussed earlier and
Search WWH ::

Custom Search