Hardware Reference
In-Depth Information
known. Otherwise, sequential fetching and executing continue. As
Figure C.18
shows, if the
prediction turns out to be wrong, the prediction bits are changed.
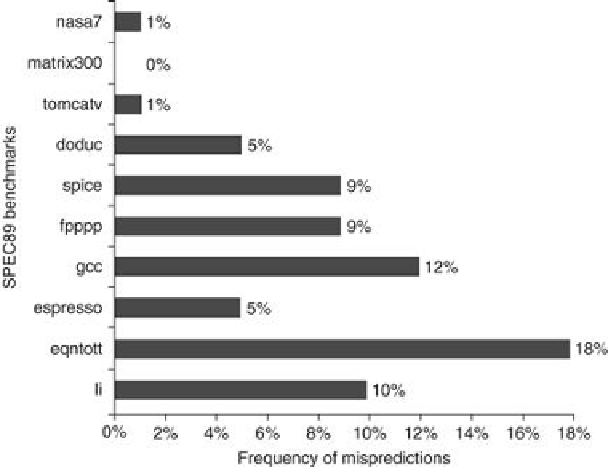
What kind of accuracy can be expected from a branch-prediction buffer using 2 bits per
entry on real applications?
Figure C.19
shows that for the SPEC89 benchmarks a branch-pre-
diction buffer with 4096 entries results in a prediction accuracy ranging from over 99% to 82%,
or a
misprediction rate
of 1% to 18%. A 4K entry buffer, like that used for these results, is con-
sidered small by 2005 standards, and a larger buffer could produce somewhat better results.
FIGURE C.19
Prediction accuracy of a 4096-entry 2-bit prediction buffer for the
SPEC89 benchmarks
. The misprediction rate for the integer benchmarks (gcc, espresso,
eqntott, and li) is substantially higher (average of 11%) than that for the floating-point pro-
grams (average of 4%). Omitting the floating-point kernels (nasa7, matrix300, and tomcatv)
still yields a higher accuracy for the FP benchmarks than for the integer benchmarks. These
data, as well as the rest of the data in this section, are taken from a branch-prediction study
done using the IBM Power architecture and optimized code for that system. See Pan, So, and
Rameh [1992]. Although these data are for an older version of a subset of the SPEC bench-
marks, the newer benchmarks are larger and would show slightly worse behavior, especially
for the integer benchmarks.
As we try to exploit more ILP, the accuracy of our branch prediction becomes critical. As
we can see in
Figure C.19
,
the accuracy of the predictors for integer programs, which typically
also have higher branch frequencies, is lower than for the loop-intensive scientific programs.
We can atack this problem in two ways: by increasing the size of the bufer and by increasing
the accuracy of the scheme we use for each prediction. A buffer with 4K entries, however, as
Figure C.20
shows, performs quite comparably to an infinite buffer, at least for benchmarks
like those in SPEC. The data in
Figure C.20
make it clear that the hit rate of the buffer is not
the major limiting factor. As we mentioned above, simply increasing the number of bits per
Search WWH ::

Custom Search