Hardware Reference
In-Depth Information
more commonplace, so architects must design systems to cope with these challenges. This sec-
tion gives a quick overview of the issues in dependability, leaving the official definition of the
terms and approaches to Section D.3 in Appendix D.
Computers are designed and constructed at different layers of abstraction. We can descend
recursively down through a computer seeing components enlarge themselves to full subsys-
tems until we run into individual transistors. Although some faults are widespread, like the
loss of power, many can be limited to a single component in a module. Thus, uter failure of
a module at one level may be considered merely a component error in a higher-level module.
This distinction is helpful in trying to find ways to build dependable computers.
One difficult question is deciding when a system is operating properly. This philosophical
point became concrete with the popularity of Internet services. Infrastructure providers star-
ted offering
service level agreements
(SLAs) or
service level objectives
(SLOs) to guarantee that
their networking or power service would be dependable. For example, they would pay the
customer a penalty if they did not meet an agreement more than some hours per month. Thus,
an SLA could be used to decide whether the system was up or down.
Systems alternate between two states of service with respect to an SLA:
1.
Service accomplishment
, where the service is delivered as specified2.
2.
Service interruption
, where the delivered service is different from the SLA
Transitions between these two states are caused by
failures
(from state 1 to state 2) or
restora-
tions
(2 to 1). Quantifying these transitions leads to the two main measures of dependability:
■
Module reliability
is a measure of the continuous service accomplishment (or, equivalently,
of the time to failure) from a reference initial instant. Hence, the
mean time to failure
(MTTF)
is a reliability measure. The reciprocal of MTTF is a rate of failures, generally reported
as failures per billion hours of operation, or
FIT
(for
failures in time
). Thus, an MTTF of
1,000,000 hours equals 10
9
/10
6
or 1000 FIT. Service interruption is measured as
mean time to
repair
(MTTR).
Mean time between failures
(MTBF) is simply the sum of MTTF + MTTR. Al-
though MTBF is widely used, MTTF is often the more appropriate term. If a collection of
modules has exponentially distributed lifetimes—meaning that the age of a module is not
important in probability of failure—the overall failure rate of the collection is the sum of
the failure rates of the modules.
■
Module availability
is a measure of the service accomplishment with respect to the alterna-
tion between the two states of accomplishment and interruption. For nonredundant sys-
tems with repair, module availability is
Note that reliability and availability are now quantifiable metrics, rather than synonyms for
dependability. From these definitions, we can estimate reliability of a system quantitativelyif
if we make some assumptions about the reliability of components and that failures are inde-
pendent.
Example

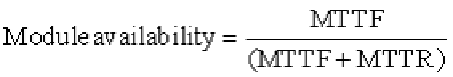
Search WWH ::

Custom Search