Hardware Reference
In-Depth Information
Similarly, as some out-of-order processors stretch the hit time, that portion of the perform-
ance equation could be divided by total hit latency less overlapped hit latency. This equation
could be further expanded to account for contention for memory resources in an out-of-order
processor by dividing total miss latency into latency without contention and latency due to
contention. Let's just concentrate on miss latency.
We now have to decide the following:
■
Length of memory latency
—What to consider as the start and the end of a memory operation
in an out-of-order processor
■
Length of latency overlap
—What is the start of overlap with the processor (or, equivalently,
when do we say a memory operation is stalling the processor)
Given the complexity of out-of-order execution processors, there is no single correct deini-
tion.
Since only commited operations are seen at the retirement pipeline stage, we say a pro-
cessor is stalled in a clock cycle if it does not retire the maximum possible number of instruc-
tions in that cycle. We atribute that stall to the irst instruction that could not be retired. This
deinition is by no means foolproof. For example, applying an optimization to improve a cer-
tain stall time may not always improve execution time because another type of stall—hidden
behind the targeted stall—may now be exposed.
For latency, we could start measuring from the time the memory instruction is queued in
the instruction window, or when the address is generated, or when the instruction is actually
sent to the memory system. Any option works as long as it is used in a consistent fashion.
Example
Let's redo the example above, but this time we assume the processor with the
longer clock cycle time supports out-of-order execution yet still has a direct-
mapped cache. Assume 30% of the 65 ns miss penalty can be overlapped; that
is, the average CPU memory stall time is now 45.5 ns.
Answer
Average memory access time for the out-of-order (OOO) computer is
The performance of the OOO cache is
Hence, despite a much slower clock cycle time and the higher miss rate of a
direct-mapped cache, the out-of-order computer can be slightly faster if it can
hide 30% of the miss penalty.

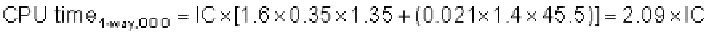
Search WWH ::

Custom Search