Hardware Reference
In-Depth Information
Substituting 65 ns for (Miss penalty × Clock cycle time), the performance of
each cache organization is
and relative performance is
In contrast to the results of average memory access time comparison, the
direct-mapped cache leads to slightly beter average performance because the
clock cycle is stretched for
all
instructions for the two-way set associative case,
even if there are fewer misses. Since CPU time is our botom-line evaluation and
since direct mapped is simpler to build, the preferred cache is direct mapped in
this example.
Miss Penalty And Out-of-Order Execution Processors
For an out-of-order execution processor, how do you define “miss penalty”? Is it the full
latency of the miss to memory, or is it just the “exposed” or nonoverlapped latency when the
processor must stall? This question does not arise in processors that stall until the data miss
completes.
Let's redefine memory stalls to lead to a new definition of miss penalty as nonoverlapped
latency:


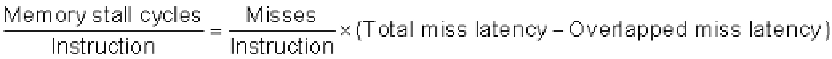
Search WWH ::

Custom Search