Hardware Reference
In-Depth Information
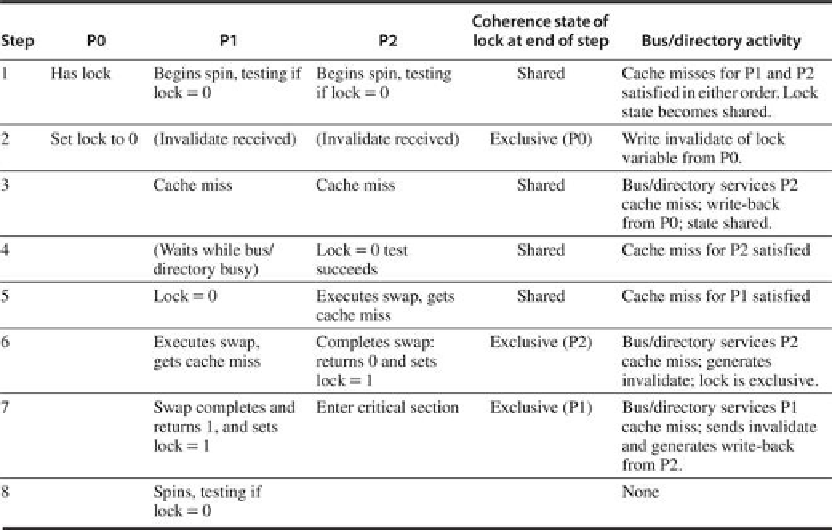
FIGURE 5.24
Cache coherence steps and bus traffic for three processors, P0, P1, and
P2
. This figure assumes write invalidate coherence. P0 starts with the lock (step 1), and the
value of the lock is 1 (i.e., locked); it is initially exclusive and owned by P0 before step 1 be-
gins. P0 exits and unlocks the lock (step 2). P1 and P2 race to see which reads the unlocked
value during the swap (steps 3 to 5). P2 wins and enters the critical section (steps 6 and 7),
while P1's attempt fails so it starts spin waiting (steps 7 and 8). In a real system, these events
will take many more than 8 clock ticks, since acquiring the bus and replying to misses take
much longer. Once step 8 is reached, the process can repeat with P2, eventually getting ex-
clusive access and setting the lock to 0.
This example shows another advantage of the load linked/store conditional primitives: The
read and write operations are explicitly separated. The load linked need not cause any bus
traic. This fact allows the following simple code sequence, which has the same characteristics
as the optimized version using exchange (
R1
has the address of the lock, the
LL
has replaced the
LD
, and the
SC
has replaced the
EXCH
):
lockit: LLR2,0(R1) ;load linked
BNEZR2,lockit ;not available-spin
DADDUIR2,R0,#1 ;locked value
SCR2,0(R1) ;store
BEQZR2,lockit ;branch if store fails
The first branch forms the spinning loop; the second branch resolves races when two pro-
cessors see the lock available simultaneously.
Search WWH ::

Custom Search