Hardware Reference
In-Depth Information
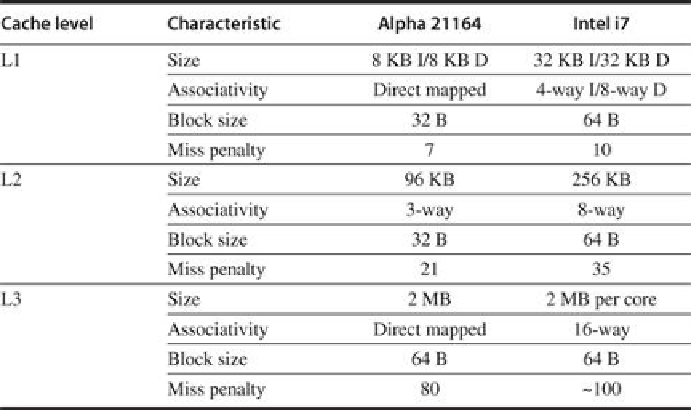
cache hierarchy, is very similar to the multicore Intel i7 and other processors, as shown in
Fig-
than on an i7. Thus, the behavior of the Alpha system should provide interesting insights into
the behavior of modern multicore designs.
FIGURE 5.9
The characteristics of the cache hierarchy of the Alpha 21164 used in this
study and the Intel i7
. Although the sizes are larger and the associativity is higher on the i7,
the miss penalties are also higher, so the behavior may differ only slightly. For example, from
Appendix B
, we can estimate the miss rates of the smaller Alpha L1 cache as 4.9% and 3%
for the larger i7 L1 cache, so the average L1 miss penalty per reference is 0.34 for the Alpha
and 0.30 for the i7. Both systems have a high penalty (125 cycles or more) for a transfer re-
quired from a private cache. The i7 also shares its L3 among all the cores.
The workload used for this study consists of three applications:
1. An online transaction-processing (OLTP) workload modeled after TPC-B (which has
Oracle 7.3.2 as the underlying database. The workload consists of a set of client processes
that generate requests and a set of servers that handle them. The server processes consume
85% of the user time, with the remaining going to the clients. Although the I/O latency is
hidden by careful tuning and enough requests to keep the processor busy, the server pro-
cesses typically block for I/O after about 25,000 instructions.
2. A decision support system (DSS) workload based on TPC-D, the older cousin of the heavily
used TPC-E, which also uses Oracle 7.3.2 as the underlying database. The workload in-
cludes only 6 of the 17 read queries in TPC-D, although the 6 queries examined in the
benchmark span the range of activities in the entire benchmark. To hide the I/O latency,
parallelism is exploited both within queries, where parallelism is detected during a query
formulation process, and across queries. Blocking calls are much less frequent than in the
OLTP benchmark; the 6 queries average about 1.5 million instructions before blocking.
Search WWH ::

Custom Search