Hardware Reference
In-Depth Information
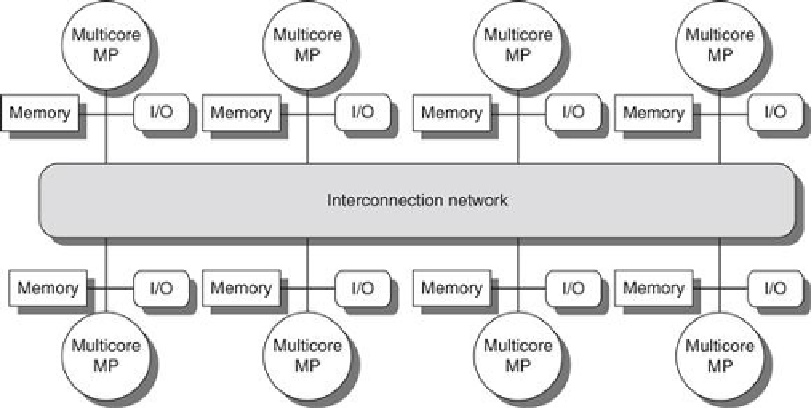
FIGURE 5.2
The basic architecture of a distributed-memory multiprocessor in 2011 typ-
ically consists of a multicore multiprocessor chip with memory and possibly I/O at-
tached and an interface to an interconnection network that connects all the nodes
.
Each processor core shares the entire memory, although the access time to the lock memory
attached to the core's chip will be much faster than the access time to remote memories.
Distributing the memory among the nodes both increases the bandwidth and reduces the
latency to local memory. A DSM multiprocessor is also called a
NUMA
(nonuniform memory
access), since the access time depends on the location of a data word in memory. The key
disadvantages for a DSM are that communicating data among processors becomes somewhat
more complex, and a DSM requires more effort in the software to take advantage of the in-
creased memory bandwidth afforded by distributed memories. Because all multicore-based
multiprocessors with more than one processor chip (or socket) use distributed memory, we
will explain the operation of distributed memory multiprocessors from this viewpoint.
In both SMP and DSM architectures, communication among threads occurs through a
shared address space, meaning that a memory reference can be made by any processor to any
memory location, assuming it has the correct access rights. The term
shared memory
associated
with both SMP and DSM refers to the fact that the
address space
is shared.
In contrast, the clusters and warehouse-scale computers of the next chapter look like indi-
vidual computers connected by a network, and the memory of one processor cannot be ac-
cessed by another processor without the assistance of software protocols running on both pro-
cessors. In such designs, message-passing protocols are used to communicate data among pro-
cessors.
Challenges Of Parallel Processing
The application of multiprocessors ranges from running independent tasks with essentially no
communication to running parallel programs where threads must communicate to complete
the task. Two important hurdles, both explainable with Amdahl's law, make parallel process-
Search WWH ::

Custom Search