Hardware Reference
In-Depth Information
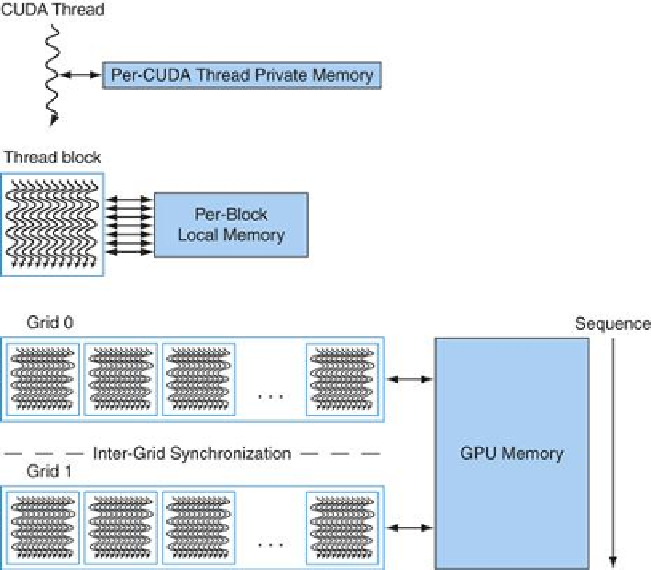
FIGURE 4.18
GPU Memory structures
. GPU Memory is shared by all Grids (vectorized
loops), Local Memory is shared by all threads of SIMD instructions within a thread block (body
of a vectorized loop), and Private Memory is private to a single CUDA Thread.
We call the on-chip memory that is local to each multithreaded SIMD Processor
Local
Memory
. It is shared by the SIMD Lanes within a multithreaded SIMD Processor, but this
memory is not shared between multithreaded SIMD Processors. The multithreaded SIMD Pro-
cessor dynamically allocates portions of the Local Memory to a thread block when it creates
the thread block, and frees the memory when all the threads of the thread block exit. That por-
tion of Local Memory is private to that thread block.
Finally, we call the off-chip DRAM shared by the whole GPU and all thread blocks
GPU
Memory
. Our vector multiply example only used GPU Memory.
The system processor, called the
host
, can read or write GPU Memory. Local Memory is un-
available to the host, as it is private to each multithreaded SIMD processor. Private Memories
are unavailable to the host as well.
Rather than rely on large caches to contain the whole working sets of an application, GPUs
traditionally use smaller streaming caches and rely on extensive multithreading of threads of
SIMD instructions to hide the long latency to DRAM, since their working sets can be hundreds
of megabytes. Given the use of multithreading to hide DRAM latency, the chip area used for
caches in system processors is spent instead on computing resources and on the large number
of registers to hold the state of many threads of SIMD instructions. In contrast, as mentioned
above, vector loads and stores amortize the latency across many elements, since they only pay
the latency once and then pipeline the rest of the accesses.
Search WWH ::

Custom Search