Hardware Reference
In-Depth Information
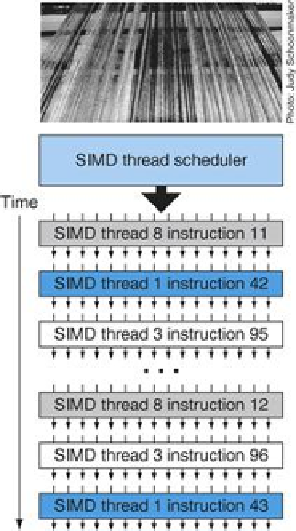
FIGURE 4.16
Scheduling of threads of SIMD instructions
. The scheduler selects a ready
thread of SIMD instructions and issues an instruction synchronously to all the SIMD Lanes ex-
ecuting the SIMD thread. Because threads of SIMD instructions are independent, the sched-
uler may select a different SIMD thread each time.
Continuing our vector multiply example, each multithreaded SIMD Processor must load
32 elements of two vectors from memory into registers, perform the multiply by reading
and writing registers, and store the product back from registers into memory. To hold these
memory elements, a SIMD Processor has an impressive 32,768 32-bit registers. Just like a vec-
tor processor, these registers are divided logically across the vector lanes or, in this case, SIMD
Lanes. Each SIMD Thread is limited to no more than 64 registers, so you might think of a SIMD
Thread as having up to 64 vector registers, with each vector register having 32 elements and
each element being 32 bits wide. (Since double-precision floating-point operands use two ad-
jacent 32-bit registers, an alternative view is that each SIMD Thread has 32 vector registers of
32 elements, each of which is 64 bits wide.)
Since Fermi has 16 physical SIMD Lanes, each contains 2048 registers. (Rather than trying to
design hardware registers with many read ports and write ports per bit, GPUs will use sim-
pler memory structures but divide them into banks to get sufficient bandwidth, just as vector
processors do.) Each CUDA Thread gets one element of each of the vector registers. To handle
the 32 elements of each thread of SIMD instructions with 16 SIMD Lanes, the CUDA Threads
of a Thread block collectively can use up to half of the 2048 registers.
To be able to execute many threads of SIMD instructions, each is dynamically allocated a
set of the physical registers on each SIMD Processor when threads of SIMD instructions are
created and freed when the SIMD Thread exits.
Search WWH ::

Custom Search