Hardware Reference
In-Depth Information
This distance separating elements to be gathered into a single register is called the
stride
. In
this example, matrix
D
has a stride of 100 double words (800 bytes), and matrix B would have
a stride of 1 double word (8 bytes). For column-major order, which is used by Fortran, the
strides would be reversed. Matrix
D
would have a stride of 1, or 1 double word (8 bytes), separ-
ating successive elements, while matrix
B
would have a stride of 100, or 100 double words (800
bytes). Thus, without reordering the loops, the compiler can't hide the long distances between
successive elements for both
B
and
D
.
Once a vector is loaded into a vector register, it acts as if it had logically adjacent elements.
Thus, a vector processor can handle strides greater than one, called
non-unit strides
, using only
vector load and vector store operations with stride capability. This ability to access nonsequen-
tial memory locations and to reshape them into a dense structure is one of the major advant-
ages of a vector processor. Caches inherently deal with unit stride data; increasing block size
can help reduce miss rates for large scientific datasets with unit stride, but increasing block
size can even have a negative effect for data that are accessed with non-unit strides. While
data efficiently that is not contiguous remains an advantage for vector processors on certain
problems, as we shall see in
Section 4.7
.
On VMIPS, where the addressable unit is a byte, the stride for our example would be 800.
The value must be computed dynamically, since the size of the matrix may not be known
at compile time or—just like vector length—may change for different executions of the same
statement. The vector stride, like the vector starting address, can be put in a general-purpose
register. Then the VMIPS instruction
LVWS
( load vector with stride) fetches the vector into a
vector register. Likewise, when storing a non-unit stride vector, use the instruction
SVWS
(store
vector with stride).
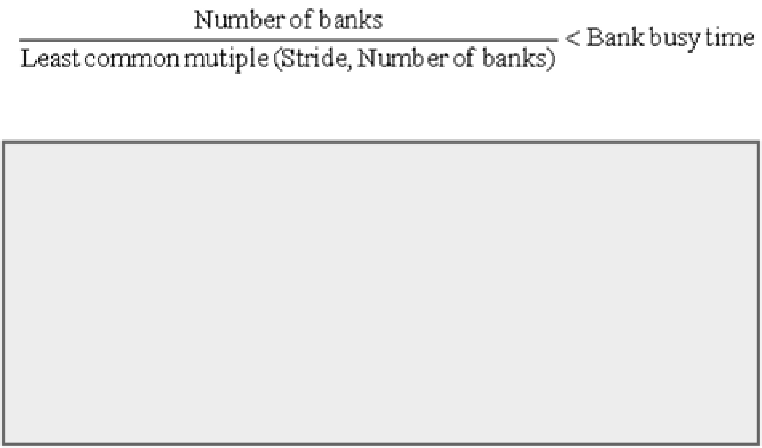
Supporting strides greater than one complicates the memory system. Once we introduce
non-unit strides, it becomes possible to request accesses from the same bank frequently. When
multiple accesses contend for a bank, a memory bank conflict occurs, thereby stalling one ac-
cess. A bank conflict and, hence, a stall will occur if
Example
Suppose we have 8 memory banks with a bank busy time of 6 clocks and a total
memory latency of 12 cycles. How long will it take to complete a 64-element
vector load with a stride of 1? With a stride of 32?
Answer
Since the number of banks is larger than the bank busy time, for a stride of 1 the
load will take 12 + 64 = 76 clock cycles, or 1.2 clock cycles per element. The worst
possible stride is a value that is a multiple of the number of memory banks, as
in this case with a stride of 32 and 8 memory banks. Every access to memory
(after the first one) will collide with the previous access and will have to wait
Search WWH ::

Custom Search