Hardware Reference
In-Depth Information
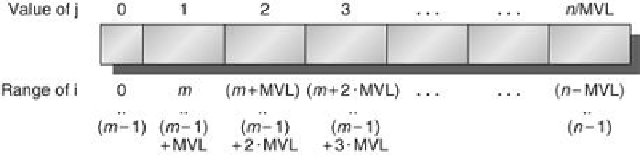
FIGURE 4.6
A vector of arbitrary length processed with strip mining
. All blocks but the
first are of length MVL, utilizing the full power of the vector processor. In this figure, we use
the variable
m
for the expression
(n % MVL)
. (The C operator % is
modulo
.)
The inner loop of the preceding code is vectorizable with length
VL
, which is equal to either
(n % MVL)
or MVL. The VLR register must be set twice in the code, once at each place where the
variable
VL
in the code is assigned.
Vector Mask Registers: Handling IF Statements In Vector Loops
From Amdahl's law, we know that the speedup on programs with low to moderate levels of
vectorization will be very limited. The presence of conditionals (IF statements) inside loops
and the use of sparse matrices are two main reasons for lower levels of vectorization. Pro-
grams that contain IF statements in loops cannot be run in vector mode using the techniques
we have discussed so far because the IF statements introduce control dependences into a loop.
Likewise, we cannot implement sparse matrices efficiently using any of the capabilities we
have seen so far. We discuss strategies for dealing with conditional execution here, leaving the
discussion of sparse matrices for later.
Consider the following loop writen in C:
for (i = 0; i < 64; i=i+1)
if (X[i] != 0)
X[i] = X[i] − Y[i];
This loop cannot normally be vectorized because of the conditional execution of the body;
however, if the inner loop could be run for the iterations for which
X[i] ≠ 0
, then the subtrac-
tion could be vectorized.
The common extension for this capability is
vector-mask control
. Mask registers essentially
provide conditional execution of each element operation in a vector instruction. The vector-
mask control uses a Boolean vector to control the execution of a vector instruction, just as con-
ditionally executed instructions use a Boolean condition to determine whether to execute a
scalar instruction. When the
vector-mask register
is enabled, any vector instructions executed
operate only on the vector elements whose corresponding entries in the vector-mask register
are one. The entries in the destination vector register that correspond to a zero in the mask
register are unaffected by the vector operation. Clearing the vector-mask register sets it to all
ones, making subsequent vector instructions operate on all vector elements. We can now use
the following code for the previous loop, assuming that the starting addresses of
X
and
Y
are in
Rx
and
Ry
, respectively:
LV
V1,Rx
;load vector X into V1
LV
V2,Ry
;load vector Y
L.D
F0,#0
;load FP zero into F0
SNEVS.D
V1,F0
;sets VM(i) to 1 if V1(i)!=F0
Search WWH ::

Custom Search