Hardware Reference
In-Depth Information
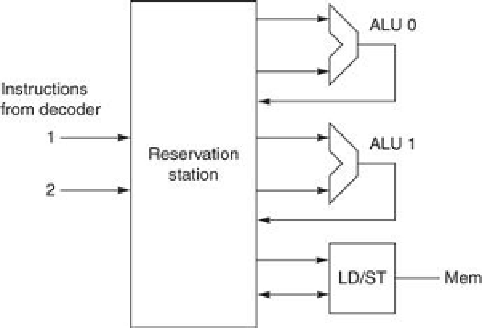
FIGURE 3.55
An out-of-order microarchitecure
.
Exercises
3.13 [25] <3.13> In this exercise, you will explore performance trade-offs between three pro-
cessors that each employ different types of multithreading. Each of these processors is su-
perscalar, uses in-order pipelines, requires a fixed three-cycle stall following all loads and
branches, and has identical L1 caches. Instructions from the same thread issued in the same
cycle are read in program order and must not contain any data or control dependences.
■ Processor A is a superscalar SMT architecture, capable of issuing up to two instruc-
tions per cycle from two threads.
■ Processor B is a fine MT architecture, capable of issuing up to four instructions per
cycle from a single thread and switches threads on any pipeline stall.
■ Processor C is a coarse MT architecture, capable of issuing up to eight instructions per
cycle from a single thread and switches threads on an L1 cache miss.
Our application is a list searcher, which scans a region of memory for a specific value stored in
R9
between the address range specified in
R16
and
R17
. It is parallelized by evenly dividing the
search space into four equal-sized contiguous blocks and assigning one search thread to each
block (yielding four threads). Most of each thread's runtime is spent in the following unrolled
loop body:
loop: LD R1,0(R16)
LD R2,8(R16)
LD R3,16(R16)
LD R4,24(R16)
LD R5,32(R16)
LD R6,40(R16)
LD R7,48(R16)
LD R8,56(R16)
BEQAL R9,R1,match0
BEQAL R9,R2,match1
Search WWH ::

Custom Search