Hardware Reference
In-Depth Information
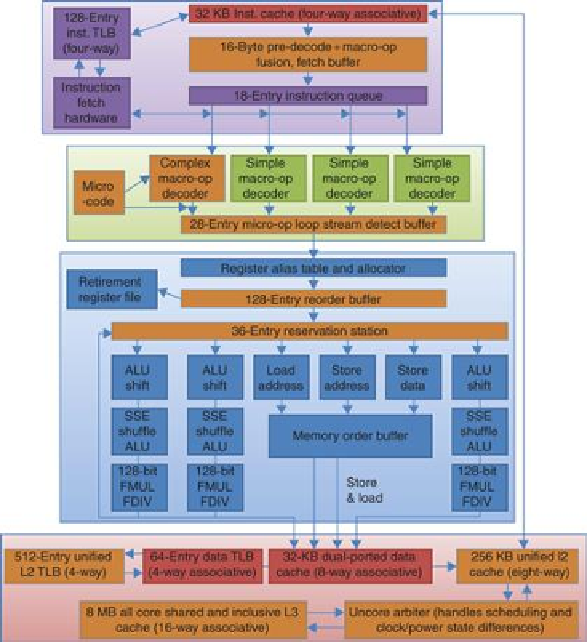
FIGURE 3.41
The Intel Core i7 pipeline structure shown with the memory system com-
ponents
. The total pipeline depth is 14 stages, with branch mispredictions costing 17 cycles.
There are 48 load and 32 store buffers. The six independent functional units can each begin
execution of a ready micro-op in the same cycle.
1. Instruction fetch—The processor uses a multilevel branch target buffer to achieve a balance
between speed and prediction accuracy. There is also a return address stack to speed up
function return. Mispredictions cause a penalty of about 15 cycles. Using the predicted ad-
dress, the instruction fetch unit fetches 16 bytes from the instruction cache.
2. The 16 bytes are placed in the predecode instruction buffer—In this step, a process called
macro-op fusion is executed.
Macro-op fusion
takes instruction combinations such as com-
pare followed by a branch and fuses them into a single operation. The predecode stage
also breaks the 16 bytes into individual x86 instructions. This predecode is nontrivial since
the length of an x86 instruction can be from 1 to 17 bytes and the predecoder must look
through a number of bytes before it knows the instruction length. Individual x86 instruc-
tions (including some fused instructions) are placed into the 18-entry instruction queue.
3. Micro-op decode—Individual x86 instructions are translated into micro-ops. Micro-ops are
simple MIPS-like instructions that can be executed directly by the pipeline; this approach
of translating the x86 instruction set into simple operations that are more easily pipelined
was introduced in the Pentium Pro in 1997 and has been used since. Three of the decoders
Search WWH ::

Custom Search