Hardware Reference
In-Depth Information
The ARM Cortex-A8
The A8 is a dual-issue, statically scheduled superscalar with dynamic issue detection, which
allows the processor to issue one or two instructions per clock.
Figure 3.36
shows the basic
pipeline structure of the 13-stage pipeline.
The A8 uses a dynamic branch predictor with a 512-entry two-way set associative branch
target buffer and a 4K-entry global history buffer, which is indexed by the branch history and
the current PC. In the event that the branch target buffer misses, a prediction is obtained from
the global history buffer, which can then be used to compute the branch address. In addition,
an eight-entry return stack is kept to track return addresses. An incorrect prediction results in
a 13-cycle penalty as the pipeline is lushed.
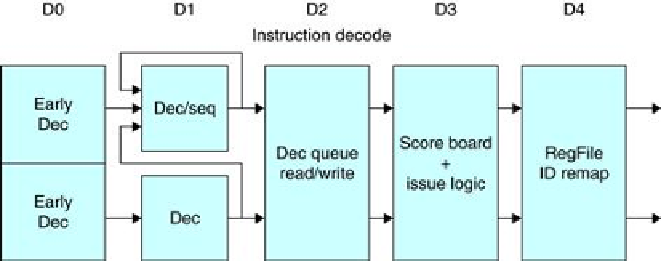
Figure 3.37
shows the instruction decode pipeline. Up to two instructions per clock can be is-
sued using an in-order issue mechanism. A simple scoreboard structure is used to track when
an instruction can issue. A pair of dependent instructions can be processed through the issue
logic, but, of course, they will be serialized at the scoreboard, unless they can be issued so that
the forwarding paths can resolve the dependence.
FIGURE 3.37
The five-stage instruction decode of the A8
. In the first stage, a PC pro-
duced by the fetch unit (either from the branch target buffer or the PC incrementer) is used to
retrieve an 8-byte block from the cache. Up to two instructions are decoded and placed into
the decode queue; if neither instruction is a branch, the PC is incremented for the next fetch.
Once in the decode queue, the scoreboard logic decides when the instructions can issue. In
the issue, the register operands are read; recall that in a simple scoreboard, the operands al-
ways come from the registers. The register operands and opcode are sent to the instruction
execution portion of the pipeline.
Figure 3.38
shows the execution pipeline for the A8 processor. Either instruction 1 for
instruction 2 can go to the load/store pipeline. Fully bypassing is supported among the
pipelines. The ARM Cortex-A8 pipeline uses a simple two-issue statically scheduled super-
scalar to allow reasonably high clock rate with lower power. In contrast, the i7 uses a reason-
ably aggressive, four-issue dynamically scheduled speculative pipeline structure.
Search WWH ::

Custom Search