Hardware Reference
In-Depth Information
This observation is critical because of the increased emphasis on integer performance since
the explosion of the World Wide Web and cloud computing starting in the mid-1990s. Indeed,
most of the market growth in the last decade—transaction processing, Web servers, and the
like—depended on integer performance, rather than floating point. As we will see in the next
section, for a realistic processor in 2011, the actual performance levels are much lower than
those shown in
Figure 3.27
.
Given the difficulty of increasing the instruction rates with realistic hardware designs, de-
signers face a challenge in deciding how best to use the limited resources available on an in-
tegrated circuit. One of the most interesting trade-offs is between simpler processors with lar-
ger caches and higher clock rates versus more emphasis on instruction-level parallelism with
a slower clock and smaller caches. The following example illustrates the challenges, and in the
next chapter we will see an alternative approach to exploiting fine-grained parallelism in the
form of GPUs.
Example
Consider the following three hypothetical, but not atypical, processors, which
we run with the SPEC gcc benchmark:
1. A simple MIPS two-issue static pipe running at a clock rate of 4 GHz and
achieving a pipeline CPI of 0.8. This processor has a cache system that
yields 0.005 misses per instruction.
2. A deeply pipelined version of a two-issue MIPS processor with slightly
smaller caches and a 5 GHz clock rate. The pipeline CPI of the processor is
1.0, and the smaller caches yield 0.0055 misses per instruction on average.
3. A speculative superscalar with a 64-entry window. It achieves one-half of
the ideal issue rate measured for this window size. (Use the data in
Figure
3.27
.) This processor has the smallest caches, which lead to 0.01 misses per
instruction, but it hides 25% of the miss penalty on every miss by dynamic
scheduling. This processor has a 2.5 GHz clock.
Assume that the main memory time (which sets the miss penalty) is 50 ns.
Determine the relative performance of these three processors.
Answer
First, we use the miss penalty and miss rate information to compute the con-
tribution to CPI from cache misses for each configuration. We do this with the
following formula:
We need to compute the miss penalties for each system:

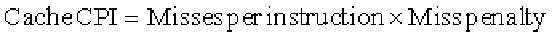
Search WWH ::

Custom Search