Hardware Reference
In-Depth Information
produce a trace of the instruction and data references. Every instruction in the trace is then
scheduled as early as possible, limited only by the data dependences. Since a trace is used,
perfect branch prediction and perfect alias analysis are easy to do. With these mechanisms,
instructions may be scheduled much earlier than they would otherwise, moving across large
numbers of instructions on which they are not data dependent, including branches, since
branches are perfectly predicted.
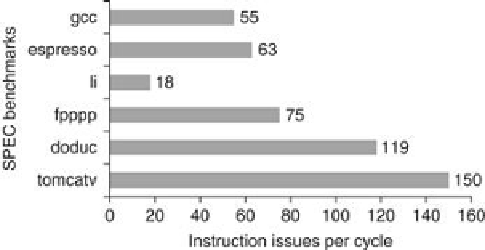
Figure 3.26
shows the average amount of parallelism available for six of the SPEC92 bench-
marks. Throughout this section the parallelism is measured by the average instruction issue
rate. Remember that all instructions have a one-cycle latency; a longer latency would reduce
the average number of instructions per clock. Three of these benchmarks (fpppp, doduc, and
tomcatv) are floating-point intensive, and the other three are integer programs. Two of the
floating-point benchmarks (fpppp and tomcatv) have extensive parallelism, which could be
exploited by a vector computer or by a multiprocessor (the structure in fpppp is quite messy,
however, since some hand transformations have been done on the code). The doduc program
has extensive parallelism, but the parallelism does not occur in simple parallel loops as it does
in fpppp and tomcatv. The program li is a LISP interpreter that has many short dependences.
FIGURE 3.26
ILP available in a perfect processor for six of the SPEC92 benchmarks
.
The first three programs are integer programs, and the last three are floating-point programs.
The floating-point programs are loop intensive and have large amounts of loop-level parallel-
ism.
Limitations On ILP For Realizable Processors
In this section we look at the performance of processors with ambitious levels of hardware
support equal to or beter than what is available in 2011 or, given the events and lessons of
the last decade, likely to be available in the near future. In particular, we assume the following
ixed atributes:
1. Up to 64 instruction issues per clock with
no
issue restrictions, or more than 10 times the
total issue width of the widest processor in 2011. As we discuss later, the practical implica-
tions of very wide issue widths on clock rate, logic complexity, and power may be the most
important limitations on exploiting ILP.
2. A tournament predictor with 1K entries and a 16-entry return predictor. This predictor is
comparable to the best predictors in 2011; the predictor is not a primary botleneck.
Search WWH ::

Custom Search