Hardware Reference
In-Depth Information
Case Studies and Exercises by Norman P. Jouppi,
Naveen Muralimanohar, and Sheng Li
Case Study 1: Optimizing Cache Performance Via
Advanced Techniques
Concepts illustrated by this case study
■ Non-blocking Caches
■ Compiler Optimizations for Caches
■ Software and Hardware Prefetching
■ Calculating Impact of Cache Performance on More Complex Processors
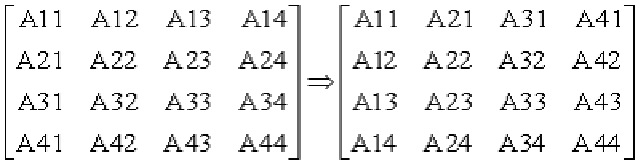
The transpose of a matrix interchanges its rows and columns; this is illustrated below:
Here is a simple C loop to show the transpose:
for (i = 0; i < 3; i++) {
for (j = 0; j < 3; j++) {
output[j][i] = input[i][j];
}
}
Assume that both the input and output matrices are stored in the row major order (
row major
order
means that the row index changes fastest). Assume that you are executing a 256 × 256
double-precision transpose on a processor with a 16 KB fully associative (don't worry about
cache conflicts) least recently used (LRU) replacement L1 data cache with 64 byte blocks. As-
sume that the L1 cache misses or prefetches require 16 cycles and always hit in the L2 cache,
and that the L2 cache can process a request every two processor cycles. Assume that each it-
eration of the inner loop above requires four cycles if the data are present in the L1 cache. As-
sume that the cache has a write-allocate fetch-on-write policy for write misses. Unrealistically,
assume that writing back dirty cache blocks requires 0 cycles.
2.1 [10/15/15/12/20] <2.2> For the simple implementation given above, this execution order
would be nonideal for the input matrix; however, applying a loop interchange optimiza-
tion would create a nonideal order for the output matrix. Because loop interchange is not
suicient to improve its performance, it must be blocked instead.
a. [10] <2.2> What should be the minimum size of the cache to take advantage of blocked
execution?
b. [15] <2.2> How do the relative number of misses in the blocked and unblocked ver-
sions compare in the minimum sized cache above?
Search WWH ::

Custom Search