Hardware Reference
In-Depth Information
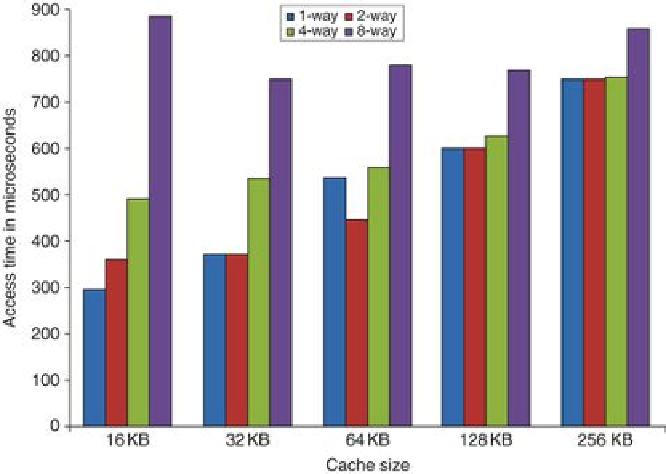
FIGURE 2.3
Access times generally increase as cache size and associativity are in-
creased
. These data come from the CACTI model 6.5 by
Tarjan, Thoziyoor, and Jouppi
[2005]
. The data assume a 40 nm feature size (which is between the technology used in In-
tel's fastest and second fastest versions of the i7 and the same as the technology used in the
fastest ARM embedded processors), a single bank, and 64-byte blocks. The assumptions
about cache layout and the complex trade-offs between interconnect delays (that depend on
the size of a cache block being accessed) and the cost of tag checks and multiplexing lead to
results that are occasionally surprising, such as the lower access time for a 64 KB with two-
way set associativity versus direct mapping. Similarly, the results with eight-way set associ-
ativity generate unusual behavior as cache size is increased. Since such observations are
highly dependent on technology and detailed design assumptions, tools such as CACTI serve
to reduce the search space rather than precision analysis of the trade-offs.
5.
Giving priority to read misses over writes to reduce miss penalty
—A write buffer is a good place
to implement this optimization. Write buffers create hazards because they hold the up-
dated value of a location needed on a read miss—that is, a read-after-write hazard through
memory. One solution is to check the contents of the write buffer on a read miss. If there
are no conflicts, and if the memory system is available, sending the read before the writes
reduces the miss penalty. Most processors give reads priority over writes. This choice has
litle effect on power consumption.
6.
Avoiding address translation during indexing of the cache to reduce hit time
—Caches must cope
with the translation of a virtual address from the processor to a physical address to access
memory. (Virtual memory is covered in
Sections 2.4
and
B.4
.
) A common optimization is to
use the page offset—the part that is identical in both virtual and physical addresses—to in-
dex the cache, as described in
Appendix B
,
page B-38. This virtual index/physical tag meth-
od introduces some system complications and/or limitations on the size and structure of
the L1 cache, but the advantages of removing the translation lookaside buffer (TLB) access
from the critical path outweigh the disadvantages.
Search WWH ::

Custom Search