Database Reference
In-Depth Information
Ideal item writing
We will write the following data into
Tbl_Book
, which we have discussed in earlier
chapters:
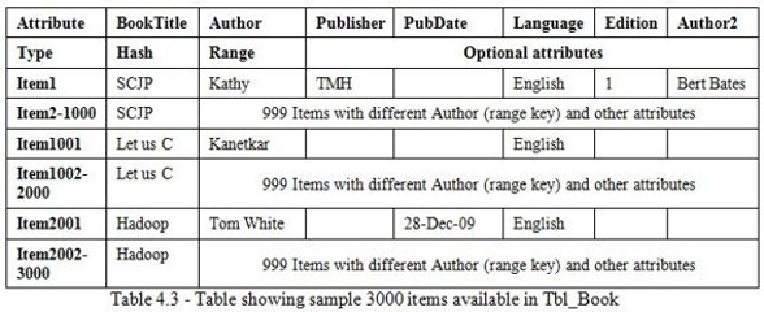
As we can see, there is a total of 3,000 book details available. Even though only three
unique book titles, namely SCJP, Let us C, and Hadoop, are available in the data, the range
key (Author) is different. So there are 1,000 different authors for the same book title. The
first 1000 items, that is Item1 to Item1000, have information about the SCJP topic (with
1000 different and unique authors) and so on.
As we already discussed horizontal partitioning and that it is done on the hash attribute,
let's assume that three partitions will be created for storing this table data. One of the parti-
tions will store the SCJP topics, the other will store Hadoop, and the third one will store
Let us C. The question is, which of the following insertions is suitable for working with
DynamoDB?
• The insertion order based on item order, that is, Item1, Item2, and Item3 through
Item3000
• The insertion order based on round-robin on the hash key, that is, Item1, then
Item1001, then Item2001, then Item1002, and so on
I hope you got the difference between the two insertions.