Image Processing Reference
In-Depth Information
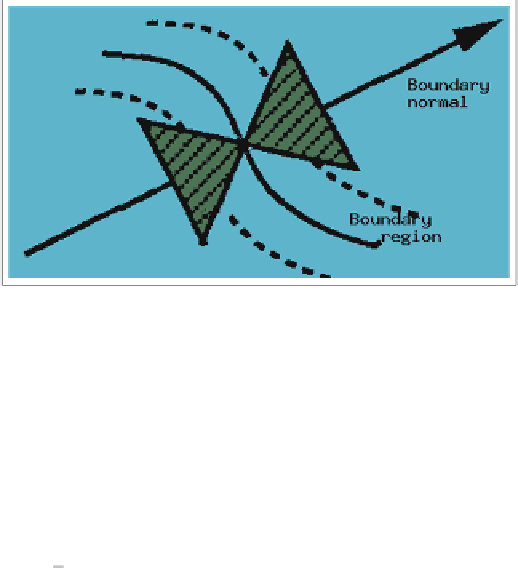
Fig. 16.2. Illustration of an oriented butterfly filter adapting to the normal direction of a
boundary point
4. Exit? If the current partitioning or the class centers have changed significantly
compared to their previous values, go to step2; else exit.
The trace of partitioning would be given by the following listing:
Circle Rectangle Star
{
2
,
10
,
12
,
7
}
3
,
1
,
9
,
6
,
13
,
15
}{
8
,
5
,
14
,
4
,
11
}
{
2
,
10
,
12
,
7
,
15
}{
1
,
3
,
6
,
9
,
4
,
13
,
11
}
5
,
8
,
14
}
{
(16.2)
2
,
10
,
12
,
7
,
15
}{
6
,
9
,
4
,
13
,
11
}{
5
,
8
,
14
,
1
,
3
}
{
2
,
10
,
12
,
7
,
15
}{
6
,
9
,
4
,
13
,
11
}{
5
,
8
,
14
,
1
,
3
}
Had we called the objects, 2
,
3
,
8
,
as star, rectangle, circle, respectively, the labels
of the result would be permuted too. Accordingly, the labels may change up to a
permutation, unless they are “learned” by the system separately.
If the clusters are not “ball”-shaped, e.g., elongated or engulfed, there is evidently a
risk of erroneous partitioning. This is also related to the distance metrics used in the
clustering. Assuming that there is a choice of metrics that can “cluster” the features
and the features themselves are powerful, then the clustering method will be able to
group the feature data meaningfully. The clustering then will implicitly or explicitly
compute a distance matrix
D
that describes the distances between all feature vectors
[
f
1
,
···
,
f
K
]:
⎛
⎞
d
1
,
1
d
1
,
2
···
d
1
,K
⎝
⎠
d
2
,
1
d
2
,
2
···
d
2
,K
D
=
(16.3)
.
.
.
.
d
K,
1
d
K,
2
···
d
K,K
Here and elsewhere in this section, we have used the notation
f
k
to mean
f
(
r
k
,L
)
for notational simplicity, i.e., the clustering is assumed to be done on feature vectors
at the highest level of the pyramid. Thus, the distance does not need to be Euclidean