Digital Signal Processing Reference
In-Depth Information
HH
H
A
HHH
HA
0
500
1000
1500
samples
(a) Stationary voiced speech
N
N
A
HH H HH H
0
500
1000
1500
samples
(b) Unvoiced speech (second frame)
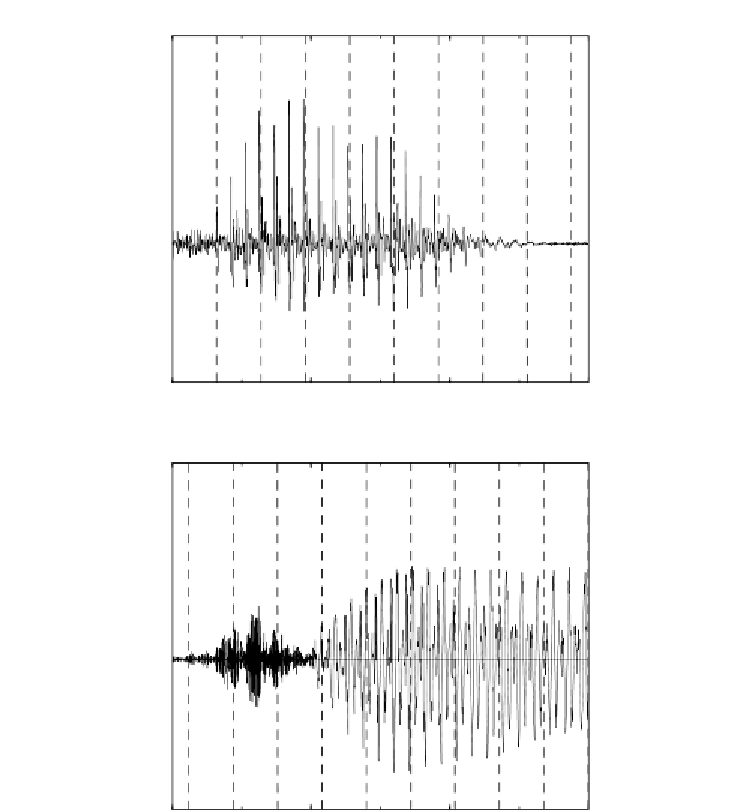
Figure 9.34
Classification of clean speech corresponding to Figure 9.33
estimation errors. Therefore, in general, in the presence of acoustic noise the
speech classification algorithmdeclaresmore frames as ACELP. These include
the silence frames of the original clean speech, unvoiced segments with lower
energy than the noise level, and the stationary voiced frames with parameter
estimation and harmonic modelling difficulties.
Neither white-noise excitation nor harmonic excitation is suitable for syn-
thesizing the background noise. The spectra of babble and vehicular noise
are not white, even after discarding the spectral envelope. synthesizing them


Search WWH ::

Custom Search