Digital Signal Processing Reference
In-Depth Information
A
H
H
H
H
H
H
H
A
0
500
1000
1500
samples
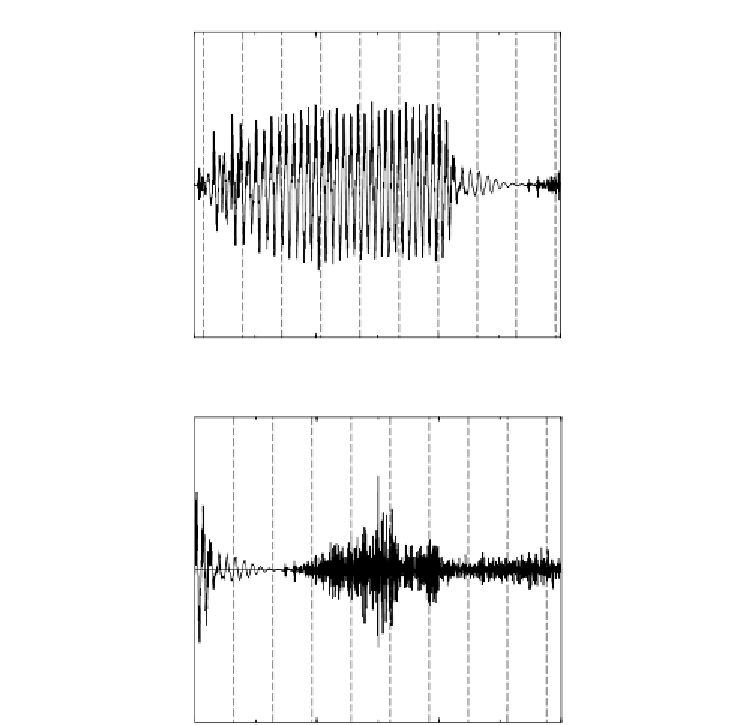
(a) Stationary voiced speech
HHA
N
N
N
N
N
N
0
500
1000
1500
samples
(b) Unvoiced speech
Figure 9.32
Classification of clean speech corresponding to Figure 9.31
the other frames are left to be encoded using either ACELP or harmonic
excitation (compare Figures 9.31b and 9.32b). The weakly-unvoiced segments
which have lower energy than the noise level are not detected as unvoiced.
When corrupted with babble or vehicular noise, the silence and the low-
energy unvoiced segments do not have the properties of unvoiced speech.
It can be seen that the energy of the noise component is comparable with
unvoiced speech and it has a significant low-frequency component (see
Figure 9.35a). This is expected since babble noise is essentially attenuated
and superimposed speech components. Figure 9.33 shows the classification
of the male speech and Figure 9.34 shows the corresponding clean speech
segments.


Search WWH ::

Custom Search