Digital Signal Processing Reference
In-Depth Information
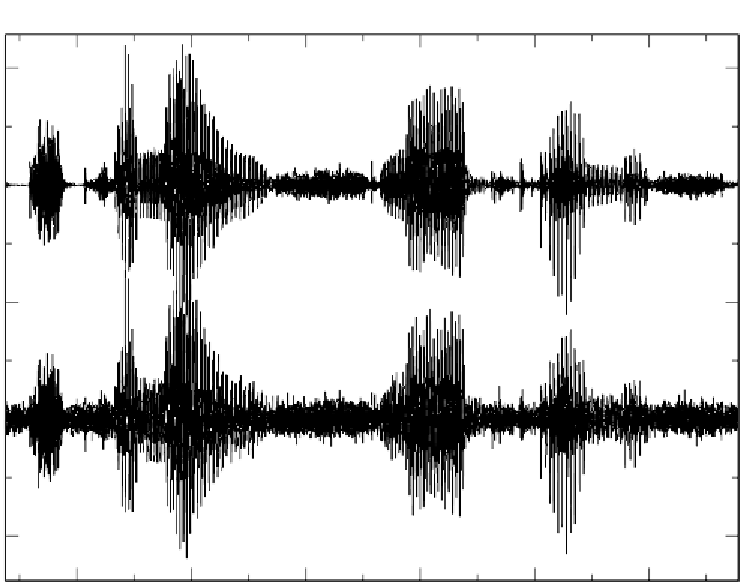
Figure 6.29
Clean (top) and 10dB SNR noisy (bottom) speech waveforms
unvoiced. The
St
can have values above 0.6 for voiced and below 0.2 for
unvoiced. Similarly
Zc
can have values below 40 and above 90 out of 160 for
voiced and unvoiced respectively.
The above hard-decision voicing method works very well with clean
background speech signals. However when speech is mixed with background
noise, the set thresholds may not be valid anymore. Hence a more careful
decision-making logic needs to be employed. Waveforms of original speech
and 10 dB SNR heavy vehicle noise are shown in Figure 6.29. As can be seen
from the figure, most unvoiced and some voiced sounds have been submerged
in the noise, making it very difficult to see them. Under noisy conditions,
voicing parameters are expected to differ considerably. The variations of
three voicing parameters (spectrum tilt, pre-emphasized energy ratio and
pitch similarity) are shown in Figure 6.30.
When there is a transition from voiced to unvoiced or unvoiced to voiced,
even during clean speech conditions, a frame can be mistakenly declared
as voiced or unvoiced since both voiced and unvoiced exist together in
that frame. It is therefore necessary to refine the voicing decision further
by introducing a mixed frame type in addition to completely voiced and
unvoiced frames. The all-important question is what proportion of the frame


Search WWH ::

Custom Search