Image Processing Reference
In-Depth Information
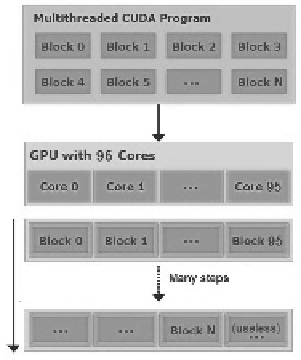
Fig. 3.5
Scheme of threads for the CUDA implementation
It shows some important features that make this new hardware architecture suitable
for further implementations of CA algorithms.
CUDA
TM
is a general purpose parallel computing architecture that allows the par-
allel NVIDIA Graphics Processors Units (GPUs) to solve many complex computa-
tional problems in a more efficient way than on a Central Processing Unit (CPU).
GPUs constitute nowadays a solid alternative for high performance computing, and
the advent of CUDA allows programmers a friendly model to accelerate a broad
range of applications. The way GPUs exploit parallelism differs from multi-core
CPUs, which raises new challenges to take advantage of its computing power. GPU
is especially well-suited to address problems that can be expressed as data-parallel
computations.
3.5.1
Examples
In [35], a parallel implementation of the Guo and Hall algorithm for CA based on
the principles described above was presented. It has been implemented by using
Microsoft Visual Studio 2008 Professional Edition (C++) with the plug-in Parallel
Nsight (CUDA
TM
) under Microsoft Windows 7 Professional with 32 bits. CUDA
TM
C, an extension of C for implementations of executable kernels in parallel with
graphical cards NVIDIA has been used to implement the CA. It has been necessary
to use the
nvcc compiler
of CUDA
TM
Toolkit and some libraries from openCV for
image input and output.
The experiments have been performed on a computer with a CPU AMD Athlon II
x4 645, which allows to work with four cores of 64 bits to 3.1 GHz. The computer
has four blocks of 512KB of L2 cache memory and 4 GB DDR3 to 1600 MHz
of main memory. The used graphical card (GPU) is an NVIDIA Geforce GT240
Search WWH ::

Custom Search