Image Processing Reference
In-Depth Information
a
b
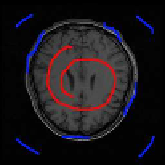
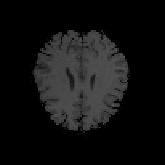
Fig. 9.2
Example of labels in image plane. (a) labeled image. (b) segmented image. The red
pixels label the object user wish to track. The blue pixels label the background to erase.
The result of these local competitions is that the strongest bacteria occupy the neigh-
boring sites and gradually spread over the image.
The calculation continues until automaton converges to stable configuration,
where cell states seize to change.This biological metaphor supplies an intuitive ex-
planation to the pseudo-code above. The examples of image labels and segmentation
results are shown in Figure 9.2.
9.3.2
Regional Cellular Automaton Segmentation
To evaluate the performance of an interactive segmentation, three indicators can be
considered: Efficiency, complexity and accuracy. A good solution should minimize
the interaction and the implementation complexity under the premise of ensuring a
higher segmentation accuracy [23] [3] [12].
The prior object edge or initial curve obtained in user interaction [21] [9] [14] is
critical to guide the contour extraction. A proper initial information could lead to a
good convergence to the true object contour.
As a well preserving edge information segmentation scheme for image, mean
shift [5] is often used as pre-segmentation, for example in a maximal similar-
ity based region merging (MSRM) method [25] with better segmentation outputs.
MSRM presents a 2D region merging based interactive image segmentation method.
The proposed method automatically merges the regions that are initially segmented
by mean shift pre-segmentation, users only need to indicate the location or regions
of the object and background with rough markers. Two non-marker regions to be
merged should have the highest similarity among all adjacent regions. Then the ob-
ject contours can be reliably extracted by labeling all the non-marker regions as
either background or object. The whole process needs not set similarity threshold in
advance. According to MSRM, the proposed scheme is divided into two stages: In
the first stage, MSRM only merges the marker background regions. For each region
B
∈
M
B
and its adjacent region
A
i
that
A
i
∈
S
B
,
S
B
=
{
A
i
}
i
=
1
,
2
,...,
r
are merged into
one region if
S
A
i
j
ρ
(
A
i
,
B
)=
max
k
ρ
(
A
i
,
)
,
A
i
∈
M
B
(9.5)
j
=
1
,
2
,...,
and the remained non-marker regions are processed in the second stage. For each
non-marker region
P
∈
N
and its adjacent region
H
i
that






Search WWH ::

Custom Search