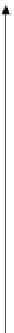Biology Reference
In-Depth Information
Y
Y
4
Y
5
Y
3
Y
2
Y
1
0
X
X
3
X
5
X
1
X
2
X
4
FIGURE 8-1.
Data points considered as intervals of confidence for each measurement.
specific mathematical criteria for optimization were formulated. Second,
our approach made the unrealistic assumption that the experimental
measurements were 100% accurate. Even the most carefully designed
and conducted experiments contain inaccuracies caused by equipment
sensitivity, experimental conditions, and similar factors. In this regard, it
may be more appropriate to consider each measurement not as an
actual data point but, rather, as an interval within which the true value
may be found with a certain probability (Figure 8-1). The length of each
interval is determined by estimating the errors in data collection.
Generally, repeated measurements will not produce the same exact
values, because of inherent measurement errors. In such scenarios, we
take the mean of all of our readings and make it our data point. This
mean is generally known with a certain precision that, intuitively, would
increase with additional measurements. To account for this effect, the
standard error of the mean
1
(SEM) is computed as the standard
deviation of all readings at a data point divided by the square root of the
number of readings. We shall not go into the details of why such a
formula was chosen. However, it defines one common method for
determining data point intervals. In Figure 8-1, the vertical lines are
centered on the observed values and represent the
1 SEM of
experimental uncertainties for the particular data point. Finally,
uncertainties in data measurements could affect the parameter estimates.
The estimates obtained for the values of the parameters therefore
should not be viewed as absolute and fixed values but, instead, as
statistical estimates themselves.
1. In this context, SEM is also called standard error of the measurement.