Information Technology Reference
In-Depth Information
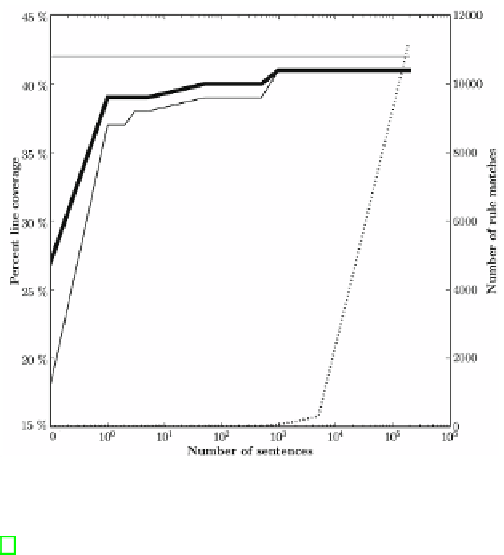
Fig. 1.
Increase in percentage of line coverage as increasing amounts of the corpus are
processed. The left
y
axis is the percent coverage. The right
y
axis is the number of
rule matches [7].
by running it on a large corpus. We tested this assumption by measuring code
coverage when a natural language processing application was run with a large
corpus as its input and with a small structured test suite as its input. The natu-
ral language processing application was a semantic parser known as OpenDMAP
[11]. It allows free mixing of terminals and non-terminals, and semantically typed
phrasal constituents, such as “gene phrases.” It has been applied to a variety of
information extraction tasks in the biomedical domain and has achieved winning
results in two shared tasks [1,9].
Code coverage
is a measure of the percentage of code in an application that is
executed during the running of a test suite. The goal is to maximize coverage—
bugs in code will not be found if the code is not executed. Various kinds of
coverage can be measured.
Line coverage
is the percentage of lines of code that
have been executed. It is the weakest indicator of code coverage.
Branch coverage
is the percentage of branches within conditionals that have been traversed. It is
more informative than line coverage.
The corpus that we employed was the largest biomedical corpus available at
the time. It consisted of 3,947,200 words. The test suite that we used was much
smaller. It contained altogether 278 test cases constructed by the application
developer. He did not monitor code coverage while designing the test suite.
Table 3 (next page) shows the results of running the application on the cor-
pus and on the test suite. As can be seen, the small test suite yielded higher
code coverage for every component of the system and every measure of code


Search WWH ::

Custom Search