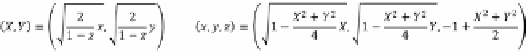Graphics Reference
In-Depth Information
In this recipe, we are encoding our normal vector so that we can reconstruct the Z component
from the X and Y components, giving a higher precision for the same amount of space in the
G-Buffer. There are a number of methods for compacting normal vectors. We have used an
approach called Lambert azimuthal equal-area projection (LAEAP) that when used with
normalized vectors is equivalent to sphere map transformations except with a slightly lower
computing cost (
Compact Normal Storage for Small G-Buffers, Pranckevičius, 2009
). LAEAP
is an azimuthal map projection commonly used in cartography for mapping the surface of a
sphere to a flat disc; the projection and its inverse are shown in the following formula. As with
other sphere map transformations, the direction of Z is preserved after encoding/decoding.
Formula to project the normalized vector (x,y,z) of a sphere to (X,Y) on a plane and its inverse using Lambert
azimuthal equal-area projection.
In addition to encoding our normal, we are then packing the encoded X and Y components
into
uint
. Packing the encoded X and Y of the normal into
uint
is not required or even
optimal, as we could easily use
SharpDX.DXGI.Format.R16G16_UNorm
for
SV_Target1
to store the
float2
directly. However, for demonstrative purposes, we have copied the X and
Y components into the low and high bits of a
SharpDX.DXGI.Format.R32_UInt
texture
using the
f32tof16
intrinsic HLSL function and bit shifting. This is a common method to
pack as much information into the smallest G-Buffer possible. Using a similar technique, we
could instead use a R32G32B32A32 format render target to pack our entire G-Buffer into a
single render target.
You may have noticed that we are not outputting the position into the G-Buffer. In order to
store the position with full precision, we would require 96 bits (3 x 32-bit floats), which on
some hardware would require the use of a 128-bit texture (or a number of additional render
targets). We could reduce the precision of the position; however, this may also introduce
visual artifacts. Instead, with modern graphics pipelines, it is possible to read directly from
the depth buffer. By using the depth buffer to reconstruct the position, we are able to save
on bandwidth, one of the key limiting factors of modern graphics hardware.
We must also consider that because GPUs often handle the depth/stencil differently to other
render targets (for example, hierarchical-Z/Hi-Z and compression), it may be worth using a
dedicated depth texture in the G-Buffer instead of the depth/stencil, especially if you want to
continue using the depth buffer later on. On modern hardware, we could use a single 128-bit
render target to store our entire G-Buffer including depth.
There's more…
It is important to realize that there is no hard and fast rule as to how and what is stored
within a G-Buffer (for example, we could also utilize unordered access views), or even how
to implement deferred rendering. There are a range of deferred rendering approaches and
alternatives, such as light prepass, tiled deferred rendering, light indexed deferred rendering,
tile-based forward rendering, Forward+ and so on.