Java Reference
In-Depth Information
Transformed
Dataset using
same build data
transformations
and statistics
Apply
Settings
New Dataset
(with
unknown
target values)
Transform,
Prepare
Data
Apply
Model
Apply
Result
Apply Data
Apply Data
´
Model
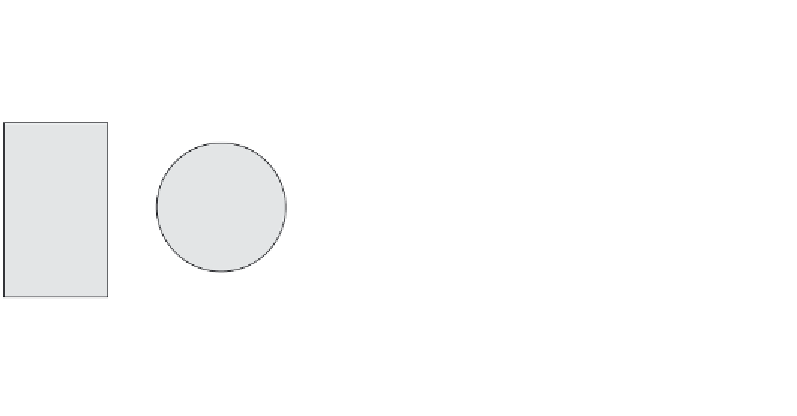
Figure 3-8
Data mining model apply process.
As illustrated in Figure 3-8, we begin with a new dataset that we
wish to apply the model to—the
apply data
. The apply data must be
transformed using the same transformations as for the build data.
This transformed dataset is then used with the model and
apply set-
tings
to produce the
apply result
. The apply settings describe the con-
tents that the user wants in the apply results (e.g., the top
prediction(s) for a case, the probability that the prediction is correct,
additional attributes carried over from the apply data, and so on).
These are explained further in Chapters 8 and 9.
The apply result is typically a table where each input case from
the apply data has a corresponding output case. A unique identifier
of the case is normally provided in the apply result so that results can
be matched to the apply data. For example, you likely want to know
which customer is predicted to respond favorably to a campaign.
3.3.3
Model Test
Model test applies only to supervised models—classification and
regression. The reason for this is that in order to test a model, you
need to know the
correct
outcome to determine how accurate the
model is. In unsupervised models, we do not have a target (known
outcome) and so there is no known value to compare. In general, we





Search WWH ::

Custom Search