Java Reference
In-Depth Information
3.1.6
Deployment Phase
The deployment phase in CRISP-DM focuses on packaging the
results of the data mining project—both the knowledge extracted
from the data as well as the process and experience mining the data
for the specific business problem—for the business users, IT depart-
ment, or business application consumer. The deployment phase may
culminate in a report, or some degree of an implementation, perhaps
as complete as an implemented and repeatable data mining solution
integrated with a business process. CRISP-DM stresses the need to
define a monitoring and maintenance strategy as part of this phase.
This involves, for example, defining when and how models will be
refreshed
, that is, rebuilt, and under what conditions. Rebuilding may
be conditional on a model meeting accuracy requirements as deter-
mined by further model testing. For unsupervised models, rebuild-
ing may be done on a periodic basis with manual review of the
model details. In either case, models may need to be rebuilt when
data statistics such as range of values or distribution changes signifi-
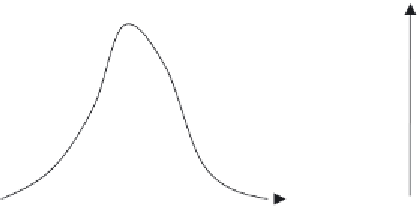
cantly as illustrated in Figure 3-2. In Figure 3-2(a) we see the attribute
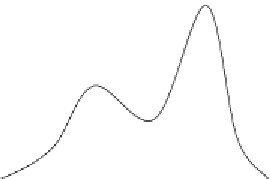
income with a fairly normal distribution. However, in Figure 3-2(b)
the distribution changes to what is called multimodal data and may
affect an existing model's quality.
Although some data mining results are useful for the knowledge
or insight they provide, businesses reap some of the most important
benefits of data mining technology when the results are deployed
in a business application or process, especially in a repeatable man-
ner. This may involve the ability to rebuild and assess models auto-
matically, or to move models from the system where they are built
to another system where data scoring occurs. For example, the
Income
Income
(b)
(a)
Figure 3-2
Attribute frequency distribution changes.



Search WWH ::

Custom Search