Java Reference
In-Depth Information
As a percentage of transactions or cases, fraud is normally quite
small, perhaps less than a few percent among all cases. A challenge
for some data mining algorithms using predictive modeling for fraud
detection is this imbalance between the number of known fraudulent
cases and nonfraudulent cases. When using classification to identify
fraud, such data can require special data preparation. A technique
called
stratified sampling
can be used to obtain a dataset that contains
a better balance. For example, if a million-case dataset contains 1 per-
cent known fraud cases, this means that for the 10,000 examples of
fraud, there are 990,000 examples of nonfraud. Many algorithms
have difficulty with this imbalance, producing models that cannot
distinguish fraud from nonfraud well. Consider that if the model
simply predicted all cases to be nonfraud, the result would be 99 per-
cent accurate, yet would not detect any fraud. By sampling the data
for 25 percent (10,000) fraudulent cases and 75 percent (30,000) non-
fraudulent cases, the algorithm can learn more effectively. When
stratified sampling is introduced,
prior probabilities
can be used to
inform the algorithm of the original population distribution, as
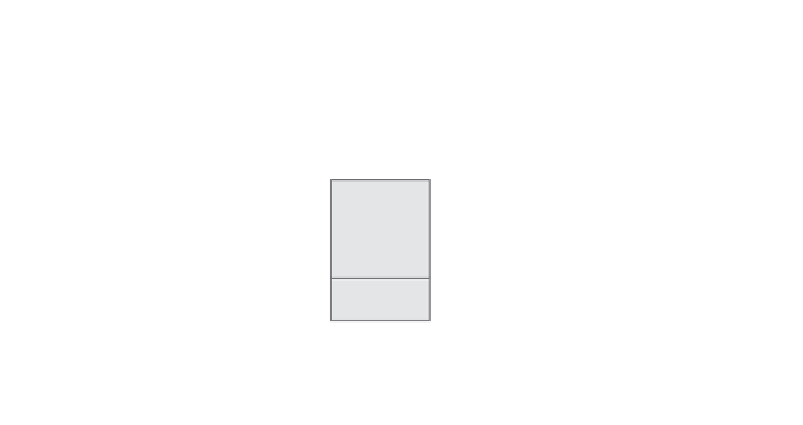
illustrated in Figure 2-5. In this example, the priors are 1 percent for
fraud
and 99 percent for
nonfraud
. We revisit this concept of prior
probability in Chapter 7. There are other techniques that can support
fraud detection such as anomaly detection, which is being intro-
duced in JDM 2.0.
Original Dataset
Target Value Distribution
for 1,000,000 Records
Stratified Sample Dataset
Target Value Distribution
for 40,000 Records
Model takes into account
the original distribution of
data when making
predictions
Stratified
Sample
Data
Build
Model
Nonfraud
99%
Nonfraud
75%
Fraud
25%
Prior Probability specification
Nonfraud = 0.99
Fraud = 0.01
Fraud 1%
Figure 2-5
Example of stratified sampling and prior probabilities.





Search WWH ::

Custom Search